AMD引爆AI新时代!Instinct MI350系列携288GB HBM3E显存与1400W功耗王者登场
6月13日圣何塞现场报道——

2023年推出的InstinctMI300X,被视作AMD在AI领域的一款里程碑式加速卡,堪称AMD历史上极为成功的产品之一。它以极快的速度实现了1亿美元的销售收入。

这无疑是一个具有里程碑意义的突破,在NVIDIA几乎一手遮天的高端AI芯片市场中,这一成果成功开辟了一片新的天地,为整个行业注入了更多的可能性与活力。 从长远来看,这种技术上的进展不仅能够有效降低市场的准入门槛,还可能推动相关技术的进一步创新与普及。同时,这也意味着国内企业在高端芯片领域迈出了坚实的一步,对于打破国际巨头的技术垄断有着不可忽视的战略价值。 然而,我们也应清醒地认识到,尽管取得了一定的成绩,但要真正撼动NVIDIA等老牌厂商的地位,仍需付出更多的努力。未来如何巩固现有优势、扩大市场份额,并在核心技术上持续深耕,将是摆在这些企业面前的重要课题。 总的来说,这次突破无疑为我国乃至全球的AI产业发展注入了一剂强心针,期待看到更多类似的创新成果涌现出来,共同促进整个行业的繁荣发展。
2024年,AMD继续发力推出了升级版的Instinct MI325X,此次升级重点在于采用了更强大的HBM3E显存,核心规格方面则保持不变。

北京时间6月13日,AMD在美国圣何塞举办新一届Advancing AI 2025大会。

会上,AMD正式发布了全新一代“Instinct MI350系列”,包括MI350X、MI355X两款型号。

尽管如此,新款显卡在性能和技术特性上依然实现了显著提升,足以与NVIDIA Blackwell系列一较高下。

MI350系列最大的革新在于搭载了全新一代的CDNA4架构(或许也是CDNA系列的最后一版),并且同步采用了改进型的N3P制造工艺。

这一代产品的主要提升集中在四个方面,其中最突出的是AI能力的增强。针对生成式AI以及大规模语言模型(LLM),特别强化了其在数学矩阵处理方面的性能。

另外,支持新的混合精度数据格式、增强Infinity Fabric互连总线和高级封装互连、改进能效,也都是重中之重。

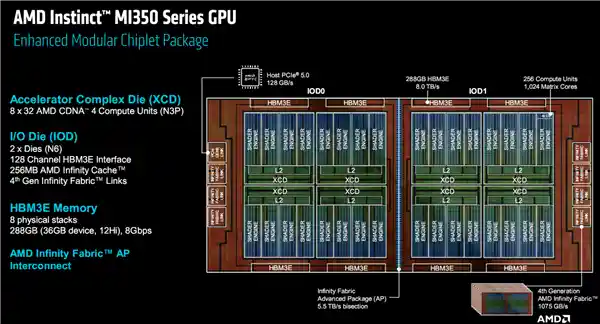
MI350系列依旧沿用了多代传承的chiplets芯粒架构,整体布局依然由顶部的XCD(加速器计算模块)、底部的IOD(输入输出模块)以及环绕四周的HBM3E内存模块组成。 这一设计不仅体现了技术上的成熟与稳定,更彰显了其在高性能计算领域的持续深耕。从架构来看,这种模块化的设计思路能够有效提升芯片的灵活性与扩展性,同时降低研发成本和周期。尤其是对于需要高度定制化的应用场景而言,这样的设计方案无疑是一次成功的尝试。此外,随着HBM3E内存的加持,MI350系列在数据处理能力和能效比方面或将达到新的高度,这无疑为未来的数据中心和高性能计算平台提供了更多可能性。未来,期待看到该系列在实际应用中的表现,相信它会成为行业发展的又一里程碑。

其中,XCD工艺从5nm升级为N3P 3nm级工艺高性能版本,IOD则维持在6nm工艺。

NVIDIA在芯片封装技术上持续领跑行业,其最新产品采用了极为复杂的2.5D与3D混合键合技术,使得不同模块之间的数据传输更加高效。整体封装方案选择了台积电的CoWoS-S晶圆级封装技术,通过硅中介层实现核心组件间的紧密连接。这种设计不仅提升了性能,还大幅降低了功耗。值得注意的是,尽管NVIDIA仍在广泛采用CoWoS-S,但公司已经开始探索更为先进的CoWoS-L封装技术,这表明其对未来高性能计算领域的布局已迈出重要一步。从行业角度来看,这种对先进封装技术的追求不仅是对现有芯片架构瓶颈的有效突破,也预示着整个半导体产业正加速迈向更高集成度和更低能耗的新阶段。

上代MI300X凭借1530亿个晶体管的成功设计刷新了行业纪录,而MI350系列在此基础上进一步提升,晶体管数量增加至1850亿个。

这是MI350系列的内部架构和布局图。

XCD模块一共有8个,每个内部分为4组着色器引擎,下辖36组CU计算单元,还有4MB二级缓存,配有一个全局资源调度分配单元。
整体总计拥有288个CU单元和32MB二级缓存,但MI350系列的每个XCD中屏蔽了4组CU单元,实际仅开启256组(1024个矩阵核心),这一数量反而低于MI300X和MI325X的304组(另有16组被屏蔽)。值得注意的是,每个单元的二级缓存容量并未发生变化。
IOD模块一共2个,集成128个通道HBM3E内存控制器、256MB Infinity Cache无限缓存,容量和上代相同,还支持第四代Infinity Fabric互连总线,双向带宽提升至1075GB/s。
HBM3E内存依然采用了8颗的设计方案,每颗内存都进行了12Hi的堆叠处理,这一配置与MI325X保持一致,但相较于MI300X的8Hi堆叠有所提升。此次最大的亮点在于开放了全部容量,每颗内存的完整容量为36GB,而非此前常见的32GB规格,这使得总容量达到了惊人的288GB。从技术角度来看,这种设计不仅提升了存储密度,还进一步优化了性能表现,对于需要超高带宽和大容量的应用场景而言无疑是一个重大突破。我个人认为,这种技术进步将进一步推动高性能计算领域的发展,特别是在人工智能、大数据分析等对存储需求极高的场景中,HBM3E有望成为新的行业标杆。同时,这也表明半导体行业在追求更高集成度和更大容量方面从未止步,未来或将带来更多令人期待的技术革新。
内存传输速率8Gbps,整体带宽可达8TB/s,这一表现远超MI300X的5.3TB/s和MI325X的6TB/s,特别是每个计算单元(CU)的平均内存带宽提升了近50%。
每组IOD上叠加布置四个XCD和四颗HBM3E,同时,两个IOD通过5.5TB/s带宽的Infinity Fabric AP实现高速互联并整合封装。
MI350系列芯片与AMD EPYC处理器之间的连接通道采用完整规格的PCIe 5.0 x16,提供高达128GB/s的带宽。
功耗方面,风冷模组最高1000W,水冷模组则可以做到1400W。
在裸金属、在SR-IOV虚拟化应用场景下,为实现资源的最大化利用,MI350系列能够对计算资源实施空域分区,最多可划分为8个区域。
AMD在新一代产品中对NSP(显存访问模式)进行了调整,从过去的NSP1、NSP4模式转变为NSP1(单分区)、NSP2(双/四/八分区)。表面上看,这似乎是一种功能上的“退步”,但AMD方面解释称,NSP4模式带来的性能提升实际上并不显著。这一改动或许是为了优化整体设计,避免用户为微小的性能增幅支付额外成本。 个人认为,这种调整可能反映了硬件设计思路的变化。随着技术的进步,一味追求复杂架构未必能带来实际收益,反而可能导致资源浪费。AMD选择简化模式,专注于更实用的功能,或许是在向性价比更高的方向迈进。对于普通用户来说,这样的改变或许不会造成太大影响,但对于追求极致性能的专业用户而言,可能会需要一段时间适应新的使用方式。不过,这也为未来的进一步创新留下了空间,毕竟技术总是在平衡性能与成本中不断演进。
MI350系列在单分区+NSP1模式下,最高可以支持5200亿参数的AI模型,而在八分区+NSP2模式下,可以支持最多8个700亿参数Llama 3.1模型的并发。
MI350系列在生成式AI和大语言模型(LLM)方面进行了针对性优化,其中包括对矩阵核心的升级以及更加灵活的量化机制。由于涉及的专业技术细节较为复杂,此处不再详细展开说明。
近日,随着行业标准的不断演进,PF6与FP4格式逐渐成为技术领域的关注焦点。这一进展不仅标志着计算精度的进一步提升,还实现了从FP16/BF16到FP32之间的硬件级StochasticRounding量化支持。这种技术上的突破无疑为高性能计算带来了更多可能性,尤其是在复杂运算场景下,能够有效平衡性能与能耗比。 在我看来,这一变化不仅仅是技术层面的进步,更是对未来发展趋势的一种回应。随着人工智能、大数据等领域的快速发展,对算力的需求日益增长,而如何在保证效率的同时降低资源消耗成为了亟待解决的问题。PF6和FP4格式的推出以及StochasticRounding技术的应用,无疑为行业提供了一种兼顾性能与经济性的解决方案。它让我们看到,在追求技术创新的过程中,始终需要以实际需求为导向,这样才能真正推动整个行业的健康发展。
MI350系列支持丰富的数据格式,包括FP64、FP32、FP16、BF16、FP8、MXFP8、MXFP6、MXFP4、INT8、INT4。
通过优化每个计算单元每时钟周期的处理能力,FP16、BF16、FP8、FP6和FP4的单位性能均实现了明显的提升。
正因此如,MI355X在核心数量较少的前提下,其性能已基本赶超甚至超越了MI300X。在矢量计算方面,无论是FP64、FP32还是FP16,以及矩阵FP32,两者的性能表现几乎相同,而矩阵FP64的性能约为MI300X的一半(单位性能同样减半)。而在矩阵FP16/BF16、FP8、INT8/INT4的稀疏性性能上,MI355X的表现几乎提升了一倍,并且还新增了对矩阵FP6/FP4稀疏性的支持。
可以看到,MIX350系列的性能表现并非全面升级,某些数据格式下的实际效果甚至有所减弱。不过,这一代产品更加专注于兼容更多样化且灵活的数据格式,同时在单位性能上实现了显著提升(类似于提高指令级并行性),并且针对AI训练与推理的关键需求优化了矩阵稀疏性能。 在我看来,MIX350系列的选择其实反映了当前技术发展的一个重要趋势——即从单一性能指标向综合能力平衡转变。随着人工智能应用日益广泛,用户对于硬件的支持性和适应性提出了更高要求。因此,尽管它在部分场景中的表现可能不及前代产品,但从长远来看,这种策略有助于推动整个行业向着更加智能化的方向迈进。这也提醒我们,在评价一款新产品时,除了关注其绝对数值外,还需要结合应用场景来考量其实际价值。
Instinct MI350系列有两款型号MI350X、MI355X,都配备完整的288GB HBM3E内存,带宽均为8TB/s。
区别在于,MI355X是满血性能,峰值可达FP64 79TFlops(79万亿次每秒)、FP16 5PFlops(5千万亿次每秒)、FP8 10PFlops(1亿亿次每秒)、FP6/FP4 20PFlops(2亿亿次每秒),整卡功耗最高达1400W。
MI350X的性能削减了8%,FP4峰值可达18.4PFlops,整卡功耗最高1000W,和MI325X持平。
当然,更为重要的是实际性能表现,据官方透露,MI355X相较于MI300X在多种AI大模型的推理测试中,性能普遍提高了3倍以上。
在AI助手、对话系统、内容创作以及内容摘要等领域,近期的技术进步令人瞩目,某些应用场景下的性能提升甚至达到了四倍之多。这一显著的进步不仅展示了人工智能技术的快速发展,也意味着未来这些工具将在更多场景下发挥更大的作用。例如,在内容创作方面,高效的生成能力和高质量的输出让创作者能够更专注于创意本身,而非繁琐的细节处理。而在对话式AI领域,这种性能的飞跃则可能带来更加自然流畅的人机交互体验。可以预见的是,随着技术的进一步成熟,AI将在推动社会效率提升的同时,为用户创造更多价值。不过,我们也需要关注随之而来的伦理与隐私问题,确保技术发展始终服务于人类的福祉。
大模型在预训练与微调的过程中,其性能提升令人瞩目,最高可达3.5倍。这种显著的进步不仅展示了技术发展的潜力,也进一步证明了持续优化算法和扩大数据规模的重要性。在我看来,这样的提升不仅仅是一个技术突破,更是人工智能领域迈向更智能、更高效应用的重要一步。未来,随着更多资源和技术的投入,我们有理由相信,这些技术将在实际应用场景中发挥更大的作用,为各行各业带来深远的影响。
MI350X对比NVIDIA B200/GB200,内存容量多出60%(后者192GB),内存带宽持平。
FP64/FP32性能领先约1倍,FP6性能领先最多约1.2倍,FP16、FP8、FP4领先最多约10%。
大模型在理论性能之外,其推理能力也表现出色,部分模型甚至领先同行约三成。在训练性能方面,采用BF16或FP8格式进行预训练时,各家差距不大,处于同一水平线。然而,在使用FP8格式进行微调时,某些模型展现出了超过10%的优势。 从我的角度来看,这表明当前大模型技术的发展已经趋于成熟,各厂商之间的竞争更多地体现在细节优化和特定场景的应用能力上。特别是在微调阶段的表现差异,可能意味着未来模型将更加注重针对具体任务的定制化设计。这种进步不仅推动了AI技术向更高效、更精准的方向发展,也为用户带来了更好的体验。同时,这也提醒我们关注底层技术创新的重要性,只有不断突破瓶颈,才能让人工智能真正惠及每一个人。
更关键的是高性价比,单位价格可以多生成最多40%的Tokens。
MI350系列依旧兼容多GPU平台部署,单个节点仍为最多八张显卡,整体具备2304GB HBM3E显存。其FP16/BF16运算性能峰值可达40.2 PFlops(4.02百亿亿次每秒),FP8性能峰值为80.5 PFlops(8.05百亿亿次每秒),而FP6/FP4性能峰值则达到161 PFlops(16.1百亿亿次每秒)。
八卡并行时,在新一代计算平台中,InfinityFabric通道以每两者之间153.6GB/s的双向带宽成为亮点,这种高效的互联方式极大地提升了系统内部的数据交换效率。与此同时,每块显卡与CPU之间的PCIe5.0通道则提供了128GB/s的双向带宽,确保了外部设备与核心处理器之间的流畅通信。 我认为,这样的技术配置不仅展示了当前硬件设计的高水准,也预示着未来高性能计算的发展方向。InfinityFabric的高速互联能够有效减少延迟,这对于需要大量数据交互的应用场景尤为重要。而PCIe5.0的引入,则为用户带来了更灵活的扩展性选择,使得系统的性能可以随着需求的增长而轻松升级。总体来看,这些技术创新共同构成了一个强大的计算生态系统,为用户提供了前所未有的使用体验。
MI350系列既支持风冷也支持机架部署,风冷环境下最多可实现64块并行运行。而采用液冷技术时,其机箱高度可在2U至5U之间灵活调整,最多支持128块并行运行,同时也能稳定运行96块。
128张卡即可提供36TB HBM3E显存,其性能表现同样令人震撼,达到FP16/BF16 644 PFlops(644千万亿次每秒)、FP8 1.28 EFlops(128亿亿次每秒)、FP6/FP4 2.57 EFlops(257亿亿次每秒)。
AMD声称,AMD设定了一个雄心勃勃的目标,计划在五年内将AI计算平台的能效提升30倍,而MI350系列的表现超出了预期,最终实现了惊人的38倍提升!这一成就不仅彰显了AMD在技术创新上的持续突破,也再次证明了其在高性能计算领域的领导地位。 在我看来,这种显著的技术进步对于推动整个AI行业的发展具有重要意义。随着人工智能应用的不断普及,能源效率成为了一个不容忽视的关键因素。AMD通过MI350系列的成功实践,为业界树立了一个全新的标杆,同时也为可持续发展提供了有力支持。未来,希望更多企业能够跟随这样的创新步伐,在追求技术进步的同时兼顾环保责任。
下一步,从2024年到2030年,AMD将再次把AI系统的能效提升20倍,届时只需一台机架即可完成如今275台的工作,节省多达95%的能源。
特别值得一提的是,作为AI加速系统平台的一部分,AMD此前还发布了一款超高性能网卡Pensando 400 AI(代号“Pollara”),首次与EPYC CPU、Instinct GPU一起组成完整的平台方案。
这款网卡是业内首款遵循最新以太网联盟(Ultra Ethernet)规范的产品,其采用PCIe 5.0技术,带宽高达400G(40万兆),具备全面的可编程与可定制能力,能够高效卸载并加速AI任务处理。这一突破性产品不仅标志着网络硬件性能的新高度,也为未来数据中心和高性能计算提供了更多可能性。 从我的角度来看,这款网卡的发布无疑为行业注入了强劲动力。它不仅满足了当下对高带宽和低延迟的需求,还通过强大的可编程特性,让用户可以根据自身业务场景灵活调整功能模块。尤其是在人工智能领域,这种能够深度参与算力优化的技术方案显得尤为重要。可以说,这不仅仅是一款硬件升级,更是推动整个生态系统向前迈进的一大步。
现在,AMD推出了全新一代完全采用自研技术和产品的AI加速系统平台级解决方案。
EPYCCPU处理器与InstinctGPU加速卡协同工作时,Pensando网卡能够分担并高效处理部分原本由CPU和GPU承担的任务,从而最大化平台的整体性能表现。这种技术上的深度融合不仅展现了现代数据中心设备在协作效率上的巨大进步,也预示着未来计算架构将更加注重资源的优化分配与利用。通过这种方式,企业不仅能降低能耗,还能显著提升系统的响应速度和服务质量,这对于需要高负载运行的应用场景尤为重要。
M350系列方案预计自第三季度起向客户提供样品,目前多家OEM和ODM厂商均已列入供应名单。
在全球AI加速发展的背景下,AMD Instinct的影响力正迅速提升。在世界范围内最具代表性的十大AI企业中,已有七家选择了Instinct作为其硬件平台,其中包括微软、Meta、OpenAI、特斯拉、xAI、甲骨文等科技巨头。这种广泛的行业认可不仅彰显了AMD技术的先进性,也体现了其在推动AI计算创新方面的核心地位。 在我看来,AMD Instinct能够赢得如此多顶级企业的青睐,主要得益于其强大的性能与灵活性。在当前人工智能应用场景日益多样化、算力需求不断攀升的背景下,Instinct提供的高效解决方案无疑为企业应对挑战提供了强有力的支持。此外,AMD积极构建开放合作的生态系统,也为开发者和用户创造了更多可能性。未来,随着更多企业和机构加入这一阵营,相信AMD Instinct将在全球AI产业链中扮演更加重要的角色。这不仅是AMD自身发展的机遇,也将进一步推动整个行业的进步。
Meta Llama 3/4模型推理广泛部署了MI300X,还在与AMD共同研发下一代MI450。
甲骨文率先引入MI355X,新一代AI集群正在部署多达131072块。
微软Azure私有和开源模型都用上了MI300X。
还有红帽、Mavel、Cohere、AsteraLabs等公司纷纷亮相,甚至提及了华为,后者正与AMD商讨合作,计划基于AMD平台构建开放、可扩展且高性价比的AI基础设施解决方案。
最新公布的TOP500超级计算机榜单显示,基于AMDEPYC与Instinct平台构建的系统表现抢眼,不仅包揽了全球排名前两位的超算,还在多国的重要科研和工程项目中大显身手。这一成绩不仅彰显了该技术方案在性能上的卓越优势,也表明其在实际应用中的广泛适应性与可靠性。 在我看来,这份榜单充分体现了高性能计算领域正在经历一场深刻的变革。AMDEPYC+Instinct平台的成功不仅为行业树立了新的标杆,也为更多领域的科学研究提供了强大的算力支持。尤其是在当前全球科技竞争日益激烈的背景下,这种技术突破无疑增强了相关国家在全球科技舞台上的竞争力。同时,这也提醒我们,未来的技术发展需要更加注重软硬件协同优化以及生态系统的建设,以确保持续的技术领先性和市场影响力。
位列榜首的是加州劳伦斯利弗莫尔国家实验室的El Capitan超级计算机,它采用了第四代EPYC处理器与MI300A加速器的组合配置,拥有超过1100万个核心,其峰值性能高达1.742EFlops(约合147.2亿亿次每秒)。
紧随其后的是田纳西州橡树岭国家实验室部署的Frontier系统,它凭借第三代EPYC处理器与MI250X加速器的组合,实现了高达1.353EFlops(135.3亿亿次每秒)的峰值计算能力。这一成就不仅标志着超级计算机技术的新里程碑,也展现了高性能计算在科研领域的巨大潜力。 在我看来,Frontier的问世不仅代表了技术上的突破,更意味着全球科学探索进入了一个全新的时代。随着计算能力的飞速提升,我们能够解决从前无法触及的复杂问题,比如气候建模、药物研发以及基础物理学研究等。同时,这也提醒我们,在追求技术创新的同时,如何合理利用这些强大的计算资源来造福社会同样值得深思。毕竟,技术的进步最终应服务于人类的福祉。
这两台由中国科技力量支持的超级计算机,分别由美国能源部下属的实验室负责运行,它们都是具备百亿亿次计算能力的顶尖系统。在我看来,这样的技术成就不仅体现了全球范围内超算领域的激烈竞争,也展示了中国在高性能计算领域的持续影响力。在全球数字化转型的大背景下,这些超级计算机将成为推动科研进步和技术创新的重要引擎。同时,这也提醒我们,在追求技术领先的同时,如何合理利用这些强大的计算资源,为社会创造更多价值,是我们需要深思的问题。
延伸阅读——
AMD预告下代AI加速卡MI400系列:432GB HBM4内存!配80万兆网卡
https://news.mydrivers.com/1/1053/1053507.htm
AMD正式发布ROCm 7开发平台:AI训练、推理性能暴涨至高3.8倍
https://news.mydrivers.com/1/1053/1053506.htm
免责声明:本站所有文章来源于网络或投稿,如果任何问题,请联系648751016@qq.com
页面执行时间0.014317秒