探索未来计算:NVIDIA GeForce RTX 50系列赋能DeepSeek智能推理模型飞速前进
近期发布的DeepSeek-R1系列模型在AI圈内引起了广泛关注,用户和开发者现在能够在个人电脑上本地运行这一具备问题解答、数学运算及编程能力的先进推理模型,同时确保了数据隐私。
得益于高达每秒执行2375万亿次运算的AI算力,NVIDIAGeForceRTX50系列GPU在运行DeepSeek系列蒸馏模型时,其速度远超目前PC市场上的任何产品。
新型推理模型
推理模型是一种新型的大规模语言模型(LLM),需要更多的时间来进行“思考”和“反思”以应对复杂的挑战,并详细说明完成任务所需的步骤。
其基本理念是,任何问题都能通过深入思考、逻辑推理和时间投入来解决,这与人类解决问题的方式相似。通过在某个问题上投入更多时间——从而进行更多的计算——大型语言模型(LLM)能够产生更优的结果。这种现象被称为测试时间尺度扩展(Test-time scaling),即在推理过程中,模型会动态分配计算资源,以便更好地进行因果推理。
推理模型通过深入理解用户需求,代表用户执行操作,并允许用户对其决策过程进行反馈,能够显著提升个人电脑用户的使用体验。这种技术的进步不仅使智能代理能够更高效地处理复杂多步骤的任务,如市场研究分析、解决高难度数学问题以及调试程序代码等,还为用户提供了更为直观的交互方式。它不仅能提高工作效率,还能让用户在日常工作中更加得心应手,极大地丰富了人机互动的体验。随着这项技术的不断成熟与普及,我们有理由相信未来的人工智能助手将变得更加智能和贴心,成为我们生活和工作的得力助手。
DeepSeek 的不同之处
DeepSeek-R1系列蒸馏模型依托于一个拥有6710亿参数的混合专家模型(MoE)。该MoE模型由多个专注于解决复杂问题的小型专家模型组成。DeepSeek模型在此基础上进一步细化分工,并将子任务委派给规模更小的专家团队。
DeepSeek利用蒸馏技术,基于一个包含6710亿个参数的巨大DeepSeek模型,创建了一系列六个较小的学生模型,这些模型的参数量从15亿到700亿不等。这一过程将大模型的推理能力传授给了较小的Llama和Qwen学生模型,从而生成了能够在本地RTXAIPC上高效运行的强大且高性能的小型推理模型。
RTX 上的峰值性能
对于这种新型的因果推理模型而言,推理速度是至关重要的因素。GeForce RTX 50系列GPU配备了专门设计的第五代Tensor Core,这些核心采用了与NVIDIA Blackwell GPU相同的基础架构,这一架构为全球领先的数据中心AI创新提供了强大的支持。RTX能够为DeepSeek进行全面加速,在个人电脑上实现卓越的推理性能。
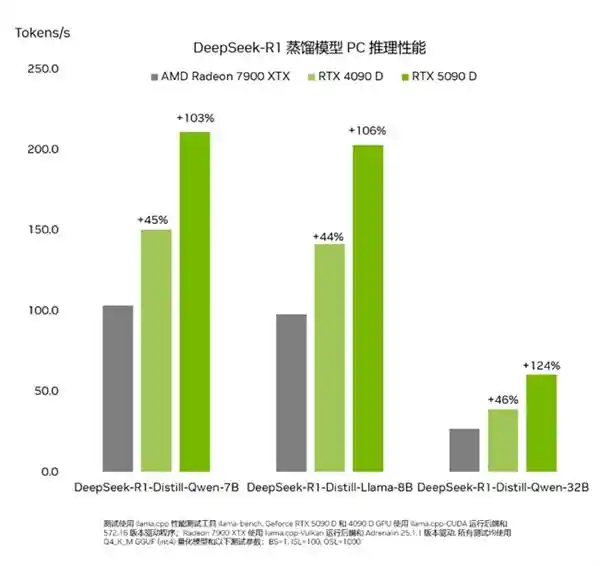
Deepseek-R1 系列蒸馏模型在 PC 上的不同 GPU 之间的吞吐量性能。
借助 RTX 体验 DeepSeek
NVIDIA的RTX AI平台凭借其丰富的AI工具、软件开发套件和模型,正为全球超过1亿台NVIDIA RTX AI PC(其中包括由GeForce RTX 50系列GPU提供支持的PC)带来前所未有的便捷与高效。DeepSeek-R1功能的引入,不仅使这些设备的功能得到显著提升,还进一步推动了AI技术在各个领域的应用和发展。 这种技术进步无疑为AI开发者和爱好者们开辟了一个全新的探索空间。通过利用如此强大的计算资源,我们可以期待看到更多创新的应用和服务出现,这不仅会极大地丰富我们的数字生活体验,还会在医疗、教育、娱乐等多个领域引发深刻的变革。同时,这也提醒我们,随着技术的发展,如何确保这些先进工具被负责任地使用,避免潜在的风险,是我们需要共同面对的重要议题。
高性能RTX GPU能够确保AI功能在没有互联网连接的情况下依然可以使用,从而实现更低的延迟,并增强用户的隐私保护。因为用户无需将敏感信息上传至云端,也无需向在线服务提供他们的问答数据。 这样的设计不仅提升了用户体验,还强化了个人数据的安全性。在当前数据泄露事件频发的时代,这种本地处理的方式显得尤为重要。它让用户能够更加放心地利用AI技术,而不必担心隐私泄露的风险。此外,低延迟的特性也使得AI应用在各种场景下都能更加流畅地运行,进一步拓宽了其适用范围。
您可以通过丰富的软件生态系统,包括Llama.cpp、Ollama、LMStudio、AnythingLLM、Jan.AI、GPT4All和OpenWebUI来体验DeepSeek-R1和RTXAIPC的强大功能,进而进行推理。此外,您还可以利用Unsloth平台对这些模型进行基于自定义数据的微调。
免责声明:本站所有文章来源于网络或投稿,如果任何问题,请联系648751016@qq.com
页面执行时间0.012863秒