「AI颠覆搜索引擎!DeepSeek-V3/R1,让智能搜索改变你的世界!」
2月3日消息,今日阿里云宣布,阿里云PAIModelGallery现已支持在云端一键部署DeepSeek-V3和DeepSeek-R1模型。
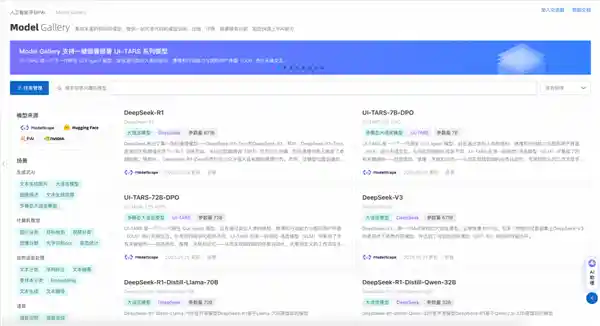
用户无需编写代码,就能借助阿里云平台完成从模型训练到部署直至推理的全部过程,显著简化了AI模型的开发流程。
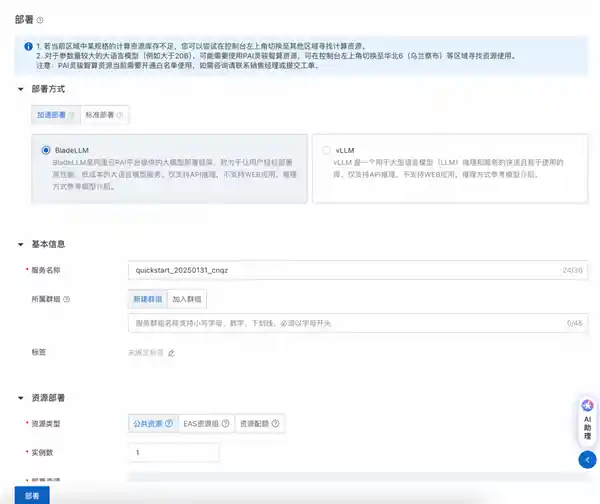
按照官方说明,部署DeepSeek模型的操作流程十分简便,总共只需遵循这三步:
登陆PAI控制台,在左侧导航栏选择工作空间列表,单击指定工作空间名称,进入对应工作空间内,最后在左侧导航栏选择快速开始>Model Gallery。
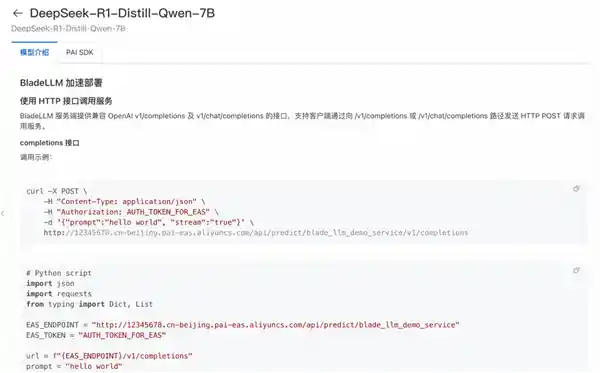
进入DeepSeek模型详情页。在Model Gallery页面的模型列表中,单击找到并点击需要部署的模型卡片,例如“DeepSeek-R1-Distill-Qwen-7B”模型,进入模型详情页面。
近期,DeepSeek模型生成服务的一键部署功能得到了显著增强。目前,DeepSeek-R1版本已支持通过vLLM技术进行加速部署,这无疑为用户提供了更为便捷的选择。对于DeepSeek-V3版本而言,除了可以利用vLLM技术实现高效部署之外,还支持Web应用部署,大大提升了用户体验。值得一提的是,DeepSeek-R1的蒸馏小模型现在也加入了BladeLLM和vLLM的加速部署选项,这不仅提高了模型运行效率,也为开发者提供了更多灵活选择。 这样的更新无疑为深度学习领域的研究者和爱好者们带来了福音,使得他们能够更加便捷地获取和使用这些先进的模型工具。同时,这也预示着未来人工智能领域的发展趋势,即技术的不断进步与优化将极大降低开发者的使用门槛,推动更多创新成果的涌现。
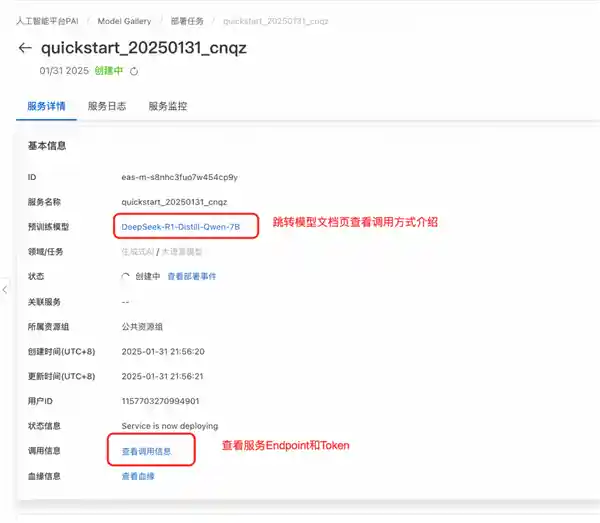
部署成功后,在服务页面上,用户可以通过点击“查看调用信息”来获取调用所需的Endpoint和Token。如果对服务调用方式有疑问,可以点击预训练模型链接,进入模型介绍页查看详细的调用方法说明。这种设计让用户能够更方便地掌握调用服务的具体步骤,从而提高工作效率。不过,为了进一步提升用户体验,建议平台能够提供更多的交互式教程或示例代码,帮助用户更快地熟悉和掌握这些技术细节。这样的改进不仅有助于吸引新用户,也能让现有用户更加满意。
经过优化处理的DeepSeek-R1-Distill-Qwen-7B模型,是在DeepSeek-R1的基础上进行了一定的技术改进,利用蒸馏技术将复杂模型的推理能力转移到了更小巧的Qwen模型上。这种做法不仅显著提升了模型的运行效率,还大大降低了对硬件资源的需求,使得更多的用户能够享受到高效、便捷的智能服务。 这样的技术进步无疑为人工智能领域带来了新的活力,特别是在资源有限的情况下仍能提供强大性能的解决方案,这将极大地推动AI技术在各个行业的普及与应用。
同时,阿里云PAI Model Gallery也提供DeepSeek-R1、DeepSeek-V3原始模型的一键部署。
免责声明:本站所有文章来源于网络或投稿,如果任何问题,请联系648751016@qq.com
页面执行时间0.010262秒