AI大盗Meta:数十TB盗版电子书背后的黑色产业链曝光!
2月9日消息,据媒体报道,一位图书作者对Meta发起诉讼,指控该公司未经许可擅自下载了大量盗版电子书,用于其AI模型的训练。
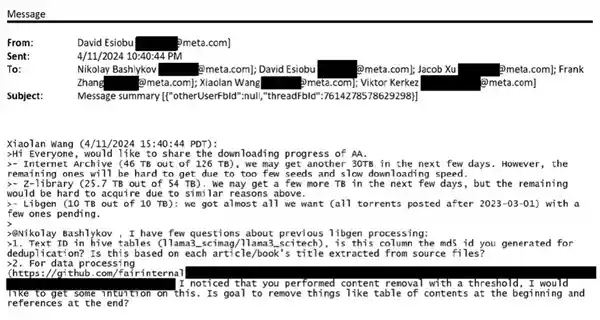
最新泄露的邮件显示,Meta承认下载了一组有争议的大规模数据集LibGen,其中包含了数千万本盗版书籍。

根据法庭文件,Meta通过一个名为“安娜的档案”(Anna's Archive)的秘密渠道下载了至少81.7TB的数据,这些数据中包含了来自知名盗版网站Z-Library和LibGen的至少35.7TB的内容。此外,Meta还被指在此之前从LibGen下载了额外的80.6TB数据。 这一系列事件引发了对Meta公司隐私政策和数据收集方式的严重质疑。如此大量的数据下载不仅涉及版权问题,还可能触及用户隐私保护的问题。这样的行为无疑加剧了公众对于科技巨头如何管理和使用个人数据的担忧。Meta公司需要对此做出解释,并采取措施来确保未来的透明度和合规性。
作者指出,Meta的这一行为构成了非法的电子书库种子下载,且这一数字可能只是其盗版行为的冰山一角。
作者估计,这些盗版电子书库可能仅占Meta盗版版权作品总量的0.008%,这似乎只是冰山一角,表明Meta平台上的盗版行为可能比我们当前了解到的情况要严重得多。这一发现不仅揭示了数字时代版权保护面临的巨大挑战,也提醒我们需要更加严格的监管措施来打击此类非法活动。
邮件还显示,2023年4月,Meta公司的研究工程师尼古拉·巴什利科夫在电子邮件中提到:“使用公司的笔记本电脑进行BT下载总让我感到不太妥当。”
到2023年9月,巴什科夫进一步强化了抗议行动,并寻求了法律专家的意见。他表示,使用Torrents进行文件传输实际上是在“播种”,即向外分享内容,这种行为在法律上是被禁止的。
尽管如此,Meta还是决定继续推进该项目,并试图通过将数据集下载到非自家服务器上来降低被追踪的风险。
免责声明:本站所有文章来源于网络或投稿,如果任何问题,请联系648751016@qq.com
页面执行时间0.008295秒