开创AI未来,共赢开源社区——MindSpore V3重磅发布!
摘要:昇思已支持在昇腾集群上训练和推理DeepSeek-V3 671B
近日,基于昇腾AI硬件及昇思MindSpore AI框架版本的DeepSeek-V3现已完成开发并正式上线昇思开源社区,为开发者提供便捷的预训练和推理功能。该系统已成功在大型集群上完成了预训练和部署工作。
使用昇思MindSpore大模型使能套件,借助昇思的多维混合分布式能力和自动并行、Dryrun集群内存仿真等技术,天级快速适配DeepSeekV3新增的模型结构及分布式并行训练功能得以实现。此外,昇思MindSpore通过对MLA、DeepSeekMoE等网络结构的深度优化,显著提升了推理部署的效率。
当前,通过获取昇思MindSpore版DeepSeekV3开源镜像,开发者现在可以直接进行DeepSeek-V3的预训练和推理部署,这无疑为AI领域的研究与开发带来了极大的便利。这项技术的进步意味着更多的人工智能爱好者和专业人员能够更轻松地使用这一先进模型,从而推动相关领域的发展。开源项目不仅促进了知识和技术的共享,还激发了创新,使得更多的创意和解决方案得以涌现。这样的进展对于整个科技行业来说都是一个积极的信号,预示着未来会有更多的突破性成果出现。
开源链接
昇思MindSpore开源社区训练代码:
https://gitee.com/mindspore/mindformers/tree/dev/research/deepseek3
魔乐社区推理代码:
https://modelers.cn/models/MindSpore-Lab/DeepSeek-V3
以下是完整的手把手教程,助力开发者开箱即用
【预训练开箱流程】
MindSporeTransformers 支持对 DeepSeek-V3 进行预训练。项目中提供了一份预训练配置文件供参考,该配置基于128台Atlas800TA2(64G)设备,采用Wikitext-2数据集进行预训练,用户可以参照多机教程来使用这些资源。
https://gitee.com/mindspore/mindformers/tree/dev/research/deepseek3
为了方便开发者快速上手体验,本章节对配置进行了调整,将DeepSeek-V3模型的参数量进行了精简,以确保它能在单台配备64GB显存的Atlas800TA2设备上顺利启动预训练流程。 这种优化方法不仅降低了硬件门槛,使得更多的开发者能够利用有限的资源进行模型训练,同时也为未来更广泛的模型部署提供了可能。通过这种方式,即使是资源较为有限的开发者团队也能有机会接触并尝试使用这款先进的深度学习模型,从而推动技术创新与应用的普及。
一、环境介绍
准备一台Atlas 800T A2 (64G)训练服务器。MindSpore Transformers的环境依赖如下:
提供了DeepSeek-V3预训练专用Docker镜像,通过如下步骤进行使用。
1.下载Docker镜像
使用如下命令下载DeepSeek-V3预训练专用镜像:
docker pull swr.cn-central-221.ovaijisuan.com/mindformers/deepseek_v3_mindspore2.4.10-train:20250209
2.基于镜像创建容器
使用如下命令新建容器:
image_name=swr.cn-central-221.ovaijisuan.com/mindformers/deepseek_v3_mindspore2.4.10-train:20250209
docker_name=deepseek_v3
docker run -itd -u root \
--ipc=host --net=host \
--privileged \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci2 \
--device=/dev/davinci3 \
--device=/dev/davinci4 \
--device=/dev/davinci5 \
--device=/dev/davinci6 \
--device=/dev/davinci7 \
--device=/dev/davinci_manager \
--device=/dev/devmm_svm \
--device=/dev/hisi_hdc \
-v /etc/localtime:/etc/localtime \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /usr/local/Ascend/driver/tools/hccn_tool:/usr/local/bin/hccn_tool \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /var/log/npu:/usr/slog \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /etc/hccn.conf:/etc/hccn.conf \
--name "$docker_name" \
"$image_name" \
/bin/bash
3.进入容器
使用如下命令进入容器,并进入代码目录:
docker exec -ti deepseek_v3 bash
cd /home/work/mindformers
二、数据集准备
以Wikitext-2数据集为例,参照以下步骤将其转换为MegatronBIN格式的文件。
1.下载数据集和分词模型文件
○数据集下载:WikiText2数据集
https://ascend-repo-modelzoo.obs.cn-east-2.myhuaweicloud.com/MindFormers/dataset/wikitext-2/wikitext-2-v1.zip
○分词模型下载:DeepSeek-V3的tokenizer.json
https://huggingface.co/deepseek-ai/DeepSeek-V3/resolve/main/tokenizer.json?download=true
2.生成Megatron BIN格式文件
将数据集文件wiki.train.tokens和分词模型文件tokenizer.json放置在/home/work/dataset下
使用以下命令转换数据集文件
cd /home/work/mindformers/research/deepseek3
python wikitext_to_bin.py \
--input /home/work/dataset/wiki.train.tokens \
--output-prefix /home/work/dataset/wiki_4096 \
--vocab-file /home/work/dataset/tokenizer.json \
--seq-length 4096 \
--worker 1
三、单机配置样例
基于预训练配置文件pretrain_deepseek3_671b.yaml按照如下步骤操作并保存为pretrain_deepseek3_1b.yaml。
1.修改模型配置
# model config
model:
model_config:
type: DeepseekV3Config
auto_register: deepseek3_config.DeepseekV3Config
seq_length: 4096
hidden_size: 2048 # 修改为2048
num_layers: #_layers 3 # 修改为3
num_heads: 8 # 修改为8
max_position_embeddings: 4096
intermediate_size: 6144 # 修改为6144
offset: 0 # 修改为0
……
2.修改MoE配置
#moe
moe_config:
expert_num: &expert_num 16 # 修改为16
first_k_dense_replace: 1 # 修改为1
……
3.修改并行配置
# parallel config for devices num=8
parallel_config:
data_parallel: 2 # 修改为2
model_parallel: 2 # 修改为2
pipeline_stage: 2 # 修改为2
expert_parallel: 2 # 修改为2
micro_batch_num: µ_batch_num 4 # 修改为4
parallel:
parallel_optimizer_config:
optimizer_weight_shard_size: 8 # 修改为8
……
4.修改学习率配置
# lr schedule
lr_schedule:
type: ConstantWarmUpLR
warmup_steps: 20 # 修改为20
5.修改数据集配置
配置数据集路径:
# dataset
train_dataset: &train_dataset
data_loader:
type: BlendedMegatronDatasetDataLoader
config:
data_path:
- 1
- "/home/work/dataset/wiki_4096_text_document" # 修改此项为数据集路径
……
配置数据集并行通信配置路径:
# mindspore context init config
context:
ascend_config:
parallel_speed_up_json_path:
"/home/work/mindformers/research/deepseek3/parallel_speed_up.json" # 修改此项为数据集并行通信配置路径
四、拉起任务
进入代码主目录并运行以下指令以启动单个Atlas800TA2(64G)预训练任务:
cd /home/work/mindformers
bash scripts/msrun_launcher.sh "run_mindformer.py \
--register_path research/deepseek3 \
--config research/deepseek3/deepseek3_671b/pretrain_deepseek3_1b.yaml"
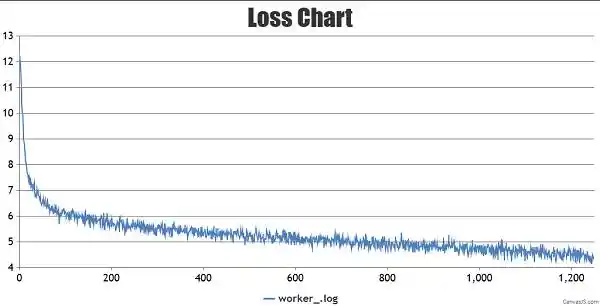
启动脚本执行完成后会继续在后台运行任务,日志文件会被保存到/home/work/mindformers/output/msrun_log目录下。若要查看训练日志,请注意,由于已启用流水线并行(pipeline_stage:2),损失值仅显示在最后那张卡的日志worker_7.log中,其他日志文件中的损失值则显示为0。
tail -f /home/work/mindformers/output/msrun_log/worker_7.log
训练loss的曲线图如下
训练过程中的权重checkpoint将会保存在/home/work/mindformers/output/checkpoint下。
【推理部署开箱流程】
采用BF16格式的模型权重文件,运行DeepSeek-V3推理服务需要4台Atlas800IA2(64G)服务器。为了加快开发部署周期,昇思MindSpore此次发布了Docker容器镜像,方便开发者快速试用。其主要操作步骤如下:
●执行以下Shell命令,下载昇思MindSpore DeepSeek-V3推理容器镜像:
docker pull
swr.cn-central-221.ovaijisuan.com/mindformers/deepseek_v3_mindspore2.5.0-infer:20250209
执行以下Shell命令,启动容器镜像,后续的操作将在容器内部完成。这种做法不仅简化了环境配置的复杂度,还提高了开发和部署的效率。通过容器化技术,我们可以更轻松地实现跨平台的兼容性,确保软件能够在不同的环境中稳定运行。这无疑为现代软件开发和运维提供了极大的便利。 这种技术的应用趋势表明,随着云计算和微服务架构的普及,容器化技术已经成为提升开发效率和系统可维护性的关键手段。它不仅简化了部署流程,还增强了系统的灵活性和可扩展性。对于企业而言,这意味着能够更快地响应市场变化,降低运营成本,并提高整体竞争力。
docker run -itd --privileged --name=deepseek-v3 --net=host \
--shm-size 500g \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci2 \
--device=/dev/davinci3 \
--device=/dev/davinci4 \
--device=/dev/davinci5 \
--device=/dev/davinci6 \
--device=/dev/davinci7 \
--device=/dev/davinci_manager \
--device=/dev/hisi_hdc \
--device /dev/devmm_svm \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /usr/local/Ascend/firmware:/usr/local/Ascend/firmware \
-v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \
-v /usr/local/sbin:/usr/local/sbin \
-v /etc/hccn.conf:/etc/hccn.conf \
deepseek_v3_mindspore2.5.0-infer:20250209 \
bash
●运行以下Shell命令,以将保存DeepSeek-V3权重文件的路径(在开箱即用的示例中为./model_path)加入白名单:
export HUB_WHITE_LIST_PATHS=./model_path
●使用以下Python脚本,从魔乐社区下载昇思MindSpore版本的DeepSeek-V3权重文件至指定路径。完整的权重文件约1.4TB,请确保指定路径下有充足的可用磁盘空间:
from openmind_hub import snapshot_download
snapshot_download(
repo_,
local_dir="./model_path",
local_dir_use_symlink=False
)
●将./模型路径/examples/predict_deepseek3_671B.yaml 文件中的 load_checkpoint 参数应设置为权重文件夹的完整路径,并且 tokenizer_file 参数和 vocab_file 参数应配置为 tokenizer.json 文件的完整路径。
在第1台到第4台服务器上,分别运行Shell命令,通过msrun_launcher.sh启动单次推理测试脚本run_deepseekv3_predict.py。任务完成后,会显示“生抽和老抽的区别是什么?”这个问题的答案。请注意,在第1台服务器上,需要将master_ip变量更新为该服务器的实际IP地址。
# 第1台服务器(Node 0)
export PYTHONPATH=/root/mindformers/:$PYTHONPATH
export HCCL_OP_EXPANSION_MODE=AIV
export MS_ENABLE_LCCL=off
master_ip=192.168.1.1
cd model_path/DeepSeek-V3/examples
bash msrun_launcher.sh "run_deepseekv3_predict.py" 32 8 $master_ip 8888 0
output/msrun_log False 300
# 第2台服务器(Node 1)
export PYTHONPATH=/root/mindformers/:$PYTHONPATH
export HCCL_OP_EXPANSION_MODE=AIV
export MS_ENABLE_LCCL=off
master_ip=192.168.1.1
cd model_path/DeepSeek-V3/examples
bash msrun_launcher.sh "run_deepseekv3_predict.py" 32 8 $master_ip 8888 1
output/msrun_log False 300
# 第3台服务器(Node 2)
export PYTHONPATH=/root/mindformers/:$PYTHONPATH
export HCCL_OP_EXPANSION_MODE=AIVexport MS_ENABLE_LCCL=off
master_ip=192.168.1.1
cd model_path/DeepSeek-V3/examples
bash msrun_launcher.sh "run_deepseekv3_predict.py" 32 8 $master_ip 8888 2 output/msrun_log False 300
# 第4台服务器(Node 3)
export PYTHONPATH=/root/mindformers/:$PYTHONPATH
export HCCL_OP_EXPANSION_MODE=AIV
export MS_ENABLE_LCCL=off
master_ip=192.168.1.1
cd model_path/DeepSeek-V3/examples
bash msrun_launcher.sh "run_deepseekv3_predict.py" 32 8 $master_ip 8888 3
output/msrun_log False 300
●此外,也可参照魔乐社区MindSpore-Lab/DeepSeek-V3模型仓库的ReadMe指南,进行推理服务化部署,随后通过访问与OpenAI兼容的RESTful服务接口,来体验多轮对话服务。
1.MindSpore支持DeepSeek V3增量模块的快速开发
DeepSeek V3的关键网络结构的支持:
●MTP:在MTP模块中,MindSpore利用shard()接口对MTP入口处的激活融合结构进行了序列并行配置,从而减少了不必要的通信重排。同时,通过set_pipeline_stage()接口实现了embedding矩阵在first_stage和last_stage之间的参数共享。具体来说,first_stage负责维护embedding的参数更新,在训练前向过程中将这些信息发送给last_stage,并在训练反向过程中从last_stage接收梯度。
AuxFreeBalance:MindSpore的MoE模块中已经集成了全局的Expert负载统计功能。AuxFreeBalance机制通过在回调函数中添加根据全局专家负载来更新专家偏置的逻辑,实现了在每次训练步骤结束时进行一次负载均衡调整的目标。这一改进有助于提高模型训练过程中的效率和稳定性,使得资源分配更加合理,避免了某些专家过载而其他专家闲置的情况。这不仅优化了训练流程,还为大规模分布式训练提供了更好的支持。从技术发展的角度来看,这样的创新体现了深度学习框架不断追求性能优化的努力方向。
●MoE Sigmoid激活:在Router score后的激活函数部分新增了可配置项,用户可以通过yaml文件灵活选择softmax或sigmoid作为激活函数,支持开发者灵活选择。
2.MindSpore对于DeepSeek V3推理网络的实现和优化
MindSpore针对DeepSeek V3的网络结构特点,高效地实现和优化了更高效的推理网络,最大化地压缩算子下发耗时和提升网络推理性能。
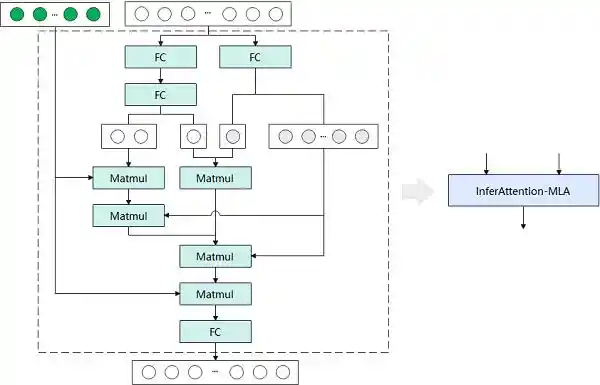
●MLA:将FC、MatMul等超过十个小型算子融合为单一的InferAttention-MLA算子,并将其与现有的PageAttention算子结合,以实现MLA模块的功能。同时,在InferAttention-MLA算子内部,设计了一种Key-Value张量存储复用机制,从而减少了存储资源的占用。
图1 MLA推理网络实现原理
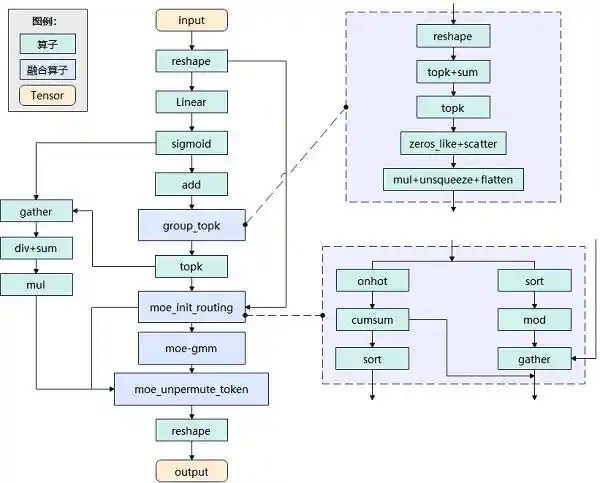
DeepSeekMoE项目对MindSpore中的MoE推理代码进行了优化,通过新增MoeUnpermuteToken、MoeInitRouting等多个融合大算子,实现了DeepSeek-V3的MoE单元组合。这些改进显著降低了单个MoE单元在推理过程中的延迟。这一系列技术进步不仅展示了MindSpore框架的强大灵活性和可扩展性,也为深度学习模型在实际应用中的性能提升提供了新的可能。这无疑为未来的大规模模型部署奠定了坚实的基础,有望推动相关领域的快速发展。
图2 DeepSeekMoE推理网络实现原理
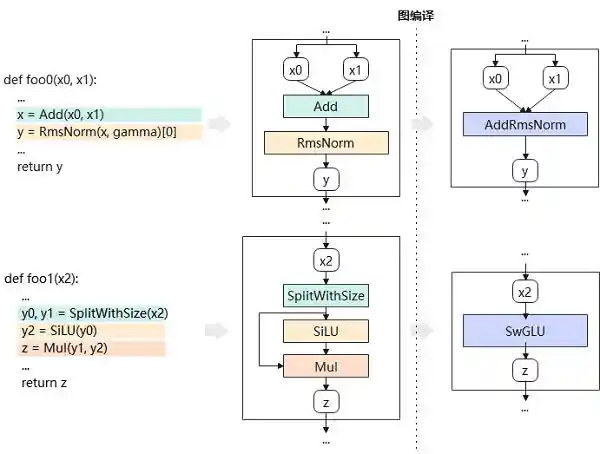
●图编译:MindSpore在推理过程中采用了图编译技术来提升性能。通过整个计算图的模式匹配,用户无需修改原有的模型代码,就能实现多种计算优化,例如AddRmsNorm、SplitWithSizeSiLUMul等操作的自动融合。以DeepSeekV3为例,在图编译阶段就实现了这些优化模式的自动融合。这种技术不仅简化了开发者的工作流程,也显著提高了模型的执行效率。可以看出,MindSpore在这方面展现出了强大的灵活性和高效性,为深度学习模型的部署提供了强有力的支持。
图3 图编译原理
3.MindSpore框架特性助力DeepSeek V3训练性能提升
DeepSeek V3的训推适配过程中,通过MindSpore的MoE模块优化、Dryrun仿真等技术,在优化MoE的训练流程的同时,还实现了更高效的多维混合并行。
在MoE模块的设计上,我们引入了多样化的配置选项,使用户能够根据需求选择不同的专家共享策略、调整路由专家的数量以及挑选合适的激活函数。这种设计显著增强了模型的适应性和灵活性。同时,在MoE并行技术的应用上,我们不仅支持传统的TP-extend-EP模式,还创新性地实现了路由序列并行和MoE计算通讯掩盖等高级并行策略。此外,分组AllToAll通讯机制也被纳入其中,以进一步提升计算效率。这些改进为用户提供了更加丰富的工具箱,让他们可以根据实际应用场景灵活选择最合适的并行加速方法。 通过这些优化措施,我们可以看到模型的训练速度和资源利用效率得到了显著提高,这无疑为大规模深度学习项目开辟了新的可能性。这些进步也表明,随着技术的不断演进,我们在追求更高性能的同时,也在努力让技术变得更加易于管理和应用。
MindSpore的Dryrun工具能够模拟集群中每块加速卡的内存使用情况,帮助优化分布式并行策略,而无需实际占用集群资源。自动负载均衡工具SAPP为DeepSeekV3提供了在内存限制下,通过精确建模内存和计算负载来寻找最佳流水线并行配置的方法。它能在几分钟内自动确定各阶段层数及重计算量,以达到最优配置。
下一步,昇思MindSpore开源社区即将推出DeepSeekV3微调样例以及R1版本镜像,这无疑将为开发者们提供一个更加便捷的开发环境。通过这一举措,不仅能够简化开发者在使用模型时的操作步骤,还能够进一步提升模型的可用性和灵活性。未来,昇思开源社区将持续利用其深厚的技术积累,不断改进DeepSeekV3系列模型的表现,从而加速从模型训练到实际应用的整个流程。这样的进步不仅为开源开发者在大模型领域的创新提供了强有力的支持,也极大地推动了各行各业向智能化转型的步伐。此举体现了昇思开源社区对技术创新的承诺,并为开发者们构建了一个高效且友好的技术生态系统。
在利用模型的过程中,如果您有任何疑问或建议,都可以通过社区渠道进行反馈。
免责声明:本站所有文章来源于网络或投稿,如果任何问题,请联系648751016@qq.com
页面执行时间0.009975秒