闪电AI:突破极限,智慧速度再进化
在AI技术迅速发展的今天,大模型已经成为推动人工智能应用落地的关键动力。然而,随着模型规模的不断增大,推理效率低和资源消耗高的问题也日益突出。为了解决这一行业难题,2025年3月3日,深度求索(DeepSeek)在首届“开源周”活动上,正式发布了首个开源代码库——FlashMLA。

1
2

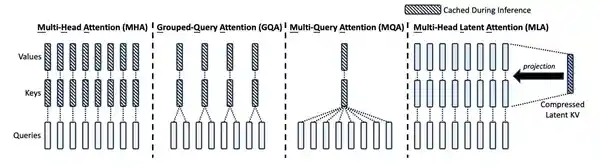
什么是 FlashMLA?
FlashMLA是一种能够使大型语言模型在H800这类GPU上运行得更加高效快速的优化策略,特别适合高要求的AI任务。该技术可以加快大型语言模型的解码速度,从而提升模型的响应速度和处理能力。这对需要实时生成的应用场景(例如聊天机器人、文本生成等)尤为关键。

3
FlashMLA的用处
1.算力调用提升,降本增效
具体来说,FlashMLA可以突破GPU算力瓶颈,降低成本。传统解码方法在处理不同长度的序列(如翻译不同长度的输入文本)时,GPU的并行计算能力会被浪费,就像用卡车运小包裹,大部分空间闲置。而FlashMLA的改进是:通过动态调度和内存优化,将Hopper GPU(如H100)的算力“榨干”,相同硬件下吞吐量显著提升。这意味着用户可以调用更少的GPU来完成同样的任务,大幅降低了推理成本。
4
2. 推理速度提升
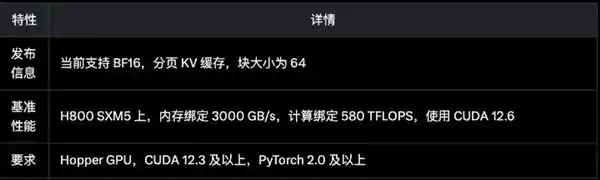
经 DeepSeek 实测,FlashMLA 在 H800 SXM5 平台上(CUDA 12.6),在内存受限配置下可达最高 3000GB/s,在计算受限配置下可达峰值 580 TFLOPS,可谓是速度提升巨大。
FlashMLA 的使用场景
实时生成任务,例如聊天机器人、文本生成以及实时翻译等应用,都需要具备低延迟和高吞吐量的特点。这些技术在当今社会的应用越来越广泛,不仅提高了工作效率,还极大地丰富了人们的日常生活体验。特别是在信息爆炸的时代,快速准确地处理和传输大量信息变得尤为重要。这些技术的发展不仅推动了人工智能领域的进步,也为各行各业带来了前所未有的机遇。例如,在医疗健康领域,通过实时翻译系统,可以实现不同语言背景下的医患交流,大大提升了医疗服务的可及性和质量。
大模型推理加速技术对于GPT和BERT这类大规模语言模型的应用至关重要。随着这些模型在自然语言处理领域的广泛应用,其庞大的参数量给实际部署带来了巨大的挑战。因此,开发出能够有效提升这些模型推理效率的技术显得尤为关键。这不仅能够帮助研究者们更快速地验证理论假设,也使得企业能够以更低的成本提供更加高效的服务。未来,随着技术的进步,我们有望看到更多创新性的方法来进一步优化这一过程,从而推动人工智能技术向更加实用化和普及化的方向发展。
通过优化算法和模型架构,企业可以显著减少对高性能GPU的需求,从而在保证计算效率的同时大幅削减推理成本。这对于资金有限的中小企业而言尤其重要,它们可以通过这种方式在不牺牲性能的前提下,更灵活地利用有限的硬件资源。这种方法不仅有助于控制运营成本,还能推动技术的普及和应用,使更多的企业能够享受到人工智能带来的便利。 这样的改进对于推动AI技术在更广泛的企业中的应用具有积极的意义。它不仅降低了技术门槛,也为中小企业提供了更多与大型企业竞争的机会。此外,这种做法还符合可持续发展的理念,减少了能源消耗,为环保做出了贡献。
5
目前该项目已支持在GitHub上下载,对于对该项目感兴趣的朋友们来说,这是一个很好的机会去亲身体验一下。你可以通过下面提供的链接自行搭建。我观察到这个项目的代码质量和文档水平都相当高,这不仅有助于开发者快速上手,也体现了开发团队的专业性和严谨态度。希望更多的人能够参与到这个项目中来,共同推动技术的发展。
https://github.com/deepseek-ai/FlashMLA,参数如下图所示;
6
当然,手握消费级显卡的朋友们也不必气馁~ 通过合理利用现有的PC硬件,本地部署一套DeepSeek-R1(INT-4)模型用于工作和学习也是个不错的选择!尤其是可以考虑使用影驰最新发布的GeForce RTX 50系列显卡来进行本地部署!
7
影驰GeForce RTX 50系列显卡采用了NVIDIA全新的Blackwell架构,并配备了第二代Transformer引擎,支持4位浮点(FP4) AI计算技术,这使得它在加速大型语言模型(LLM)和专家混合模型(MoE)的推理与训练方面具有显著优势。对于需要高性能计算能力的专业人士来说,这款显卡无疑是提升工作效率的理想选择。随着人工智能技术的不断进步,这类硬件的支持显得尤为重要。如果你正在寻找能够大幅提升生产力的显卡,那么不妨考虑一下影驰的这一新产品。欢迎感兴趣的朋友们访问影驰官方商城进行详细了解和购买。 这样的产品发布无疑为AI研究者和相关行业的专业人士带来了福音,它不仅提升了处理复杂任务的能力,也为未来的技术发展提供了坚实的基础。然而,值得注意的是,尽管这些新技术带来了显著的优势,但在实际应用中,还需要考虑到成本效益以及与其他系统组件的兼容性等问题。
免责声明:本站所有文章来源于网络或投稿,如果任何问题,请联系648751016@qq.com
页面执行时间0.009218秒