打破次元壁!全新TicVoice 7.0,让AI之音更臻完美
出门问问携手香港科技大学、上海交通大学、南洋理工大学及西北工业大学等研究机构,共同发布了新一代语音合成模型Spark-TTS,并正式推出其商业级高品质TTS引擎:TicVoice 7.0。
TicVoice7.0作为出门问问的最新一代TTS引擎,其在无需依赖额外生成模型的情况下,仅通过语言模型(序列猴子)即可实现单阶段、单流的TTS生成过程。这一技术进步不仅展示了公司在语音合成领域的深厚积累,而且使得TicVoice7.0具备了超自然的语音克隆与跨语种生成能力。更为难得的是,该系统还能够根据用户的个性化需求,定制出独一无二的精品专属声音。 这种技术创新不仅极大地提升了用户体验,也为未来的智能语音交互设定了新的标准。它表明,随着人工智能技术的不断成熟,我们正逐步迈向一个更加智能化、个性化的语音世界。在未来,我们有理由期待更多的创新应用,让语音技术更好地服务于人类社会。

目前,出门问问已将TicVoice7.0技术应用于其AI配音软件“魔音工坊”,显著提升了用户体验。这款升级后的软件不仅具备行业领先的3秒语音克隆功能,还提供了更为出色的个性化发音人定制服务。这些改进使得“魔音工坊”在客户服务、有声读物制作、情感类直播、影视解说及配音等多个领域展现出更加卓越的表现。 从这一进展来看,出门问问正致力于通过技术创新来满足用户对高质量音频内容日益增长的需求。这种专注于提升用户体验的做法无疑将有助于巩固其在智能语音领域的领先地位,并为其他科技公司树立了良好的榜样。未来,随着更多先进功能的引入,我们有理由期待该技术能够在更多场景中发挥重要作用,为用户提供更加丰富和个性化的服务体验。

TicVoice 7.0 :开启全新语音编码范式,技术 Buff 叠满
自2012年创立以来,出门问问一直致力于人工智能语音领域的研究,不断优化其TTS引擎。依托丰富的技术储备和先进的产品应用经验,出门问问陆续推出了「魔音工坊」「奇妙元」「元创岛」等语音或具备语音功能的产品,稳固地占据了行业领先的技术和产品生态地位。
近日,出门问问联合国内外顶尖的学术研究机构香港科技大学、上海交通大学、南洋理工大学、西北工业大学,开源了新一代语音生成模型 Spark-TTS,并发布于开源社区 SparkAudio。
模型一经推出,便迅速攀升至HuggingFace趋势榜TTS领域的前两名,并且增长势头十分迅猛。随着相关论文的发布,Spark-TTS再度激发了学术界的热情。
Spark-TTS或TicVoice7.0之所以引起了如此巨大的关注,主要是因为它开创了一种全新的语音编码方法,并成功地将建模架构与文本大语言模型(LLMs)的结构进行了高度整合。 这一技术革新不仅推动了语音合成领域的进步,还预示着未来人工智能在自然语言处理和语音生成方面可能达到的新高度。通过引入这种创新的语音编码方式,开发者和研究者们或许能解锁更多潜在的应用场景,从而彻底改变我们与机器交互的方式。这不仅是对现有技术的一次巨大飞跃,也标志着语音技术领域正在步入一个充满无限可能性的新时代。
直击主流语音 token 痛点
TicVoice7.0与Spark-TTS的最新技术革新为语音编码领域带来了新的突破。这一创新方案有效地应对了当前主流语音离散编码所面临的两个关键挑战。 这项新技术不仅提高了语音识别的准确性,还显著提升了语音合成的自然度,使用户在使用语音交互产品时获得更加流畅和自然的体验。这无疑是科技发展中的一个重要里程碑,预示着未来语音技术将更广泛地应用于日常生活中,从智能家居到智能客服,都将因这项技术而变得更加便捷高效。
单码本的语义 token 需要经过多个阶段才能生成声学特征,在大语言模型的自回归建模过程中,难以对音色等属性进行精准控制。
声学编码往往需要多个码本来实现,这使得模型设计变得更为复杂,并且与语义之间的联系不够紧密,从而增加了预测的不确定性和难度。
BiCodec示意图
如图所示,BiCodec技术将输入的语音分解为两个互补的部分:固定长度的GlobalToken和低码率的SemanticTokens(每秒50个令牌)。这种创新的方法在语音处理领域开辟了新的可能性。通过这种方式,我们可以更高效地存储和传输语音信息,同时确保信息的完整性。GlobalToken提供了一个全局视角,而SemanticTokens则捕捉到更细致的语音特征。这种方法不仅提高了处理效率,还为未来的语音技术和应用提供了更多的想象空间。未来,我们或许能看到更多基于这种技术的智能设备和应用,它们能够更好地理解和处理人类的语言。
GlobalToken在建模过程中主要关注时序无关的全局特征,例如音色,以此来确保语音生成的全局可控性。这种技术的应用不仅极大地提升了合成语音的自然度和一致性,还为用户提供了更多定制化选择。通过这种方式,用户能够更精细地控制最终输出的声音特质,从而满足多样化的应用场景需求。
Semantic Tokens以wav2vec2.0提取的特征作为输入,对与文本高度相关的信息进行编码,从而保证语义的高度关联性。
这种设计让BiCodec不仅能够发挥SemanticTokens在低码率和强语义关联方面的优势,还能在自回归语言模型中实现对音色等属性的精确调控,从而达到高效性和可控性的双重目标。
实现建模结构与文本 LLMs 结构的高度统一
BiCodec采用全离散、单流的编码方式,实现了语音token与文本token建模的高度统一。这种创新的方法不仅简化了多模态信息处理流程,还为语音识别和自然语言处理领域带来了新的突破。通过这种方式,不同类型的token可以更有效地进行交互和融合,从而提升了模型的整体性能和灵活性。这无疑是一个值得肯定的进步,预示着未来在人工智能领域中可能会有更多类似的跨模态技术发展。
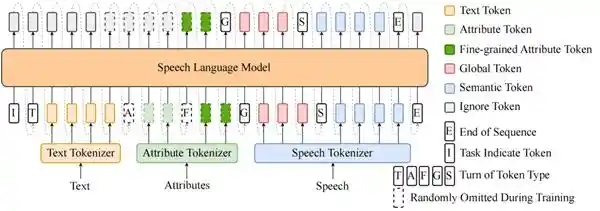
Spark-TTS在设计上直接沿用了Qwen2.5的原始架构,并在此基础上扩展了Tokenizer功能,使其能够支持与语音相关的token。这样一来,Spark-TTS的建模方式与文本建模方式达到了高度的一致性。这种做法不仅充分利用了Qwen2.5在文本处理方面的优势,还通过技术上的创新,使得语音合成任务能够在原有框架下更高效地进行。这样的设计思路显示了技术创新在推动语音合成领域发展的巨大潜力,同时也为未来更多类似的技术融合提供了有益的参考。
属性控制:通过引入属性标签(如性别、基频等级)和细粒度属性值(如精确基频),Spark-TTS 以文本+属性标签为输入,采用链式思考(CoT, Chain of Thought)的方式,依次预测细粒度属性值 → Global Tokens → Semantic Tokens,从而实现音色生成高度可控。
Spark-TTS的语言模型示意图
近日,一项新技术再次刷新了行业内的语音克隆能力标准,使得用户体验得到了极大的提升。 这项技术不仅展示了语音处理领域的最新进展,而且为用户提供了更加真实和自然的语音体验。随着人工智能技术的不断进步,这样的突破无疑会进一步推动相关产业的发展,让更多的应用场景成为可能。未来,我们有理由期待在教育、娱乐甚至日常交流等领域看到更多基于这种技术的产品和服务,它们将极大地丰富我们的生活体验。
TicVoice 7.0展现出卓越的语音克隆能力,尤其在跨语言声音克隆方面表现出色。我们分别将其与出门问问上一代产品 MeetVoice Pro及国内外优秀的同类产品做了评测,发现 TicVoice 7.0在“3秒克隆”和“至臻Pro-精品发音人”方面领先优势明显。
让 AI “说人话”,大大提升情感表现力
TicVoice7.0能够在3秒内精准捕捉声纹特征,使AI不仅能够“说人话”,还能模仿人类的叹息和停顿。与前一代的语音大模型相比,TicVoice7.0的效果得到了显著提升,经过3秒克隆测试,其国际通用MOS评分从3.9提高到了4.2。在音色相似度、情感表达以及稳定性方面,均有接近10%的改进。整体而言,新一代的语音大模型在听感上更加自然、悦耳且稳定,情感表现力也更强,这有助于提升用户在客服、情感直播、有声读物等场景中的体验。
个性化定制更加精准,轻松获得播音级配音体验
TicVoice7.0允许用户通过调节性别、语速、基频等多重参数(即将上线),精细打造个性化声音风格。特别是在“至臻Pro-精品发音人”定制服务上,用户仅需提供20至200句音频材料,即可享受到专业级别的配音体验。
相比上一代的语音大模型,TicVoice7.0在国际通用MOS评分上从4.3提高到了4.7。这表明语音生成效果极为自然,语音质量达到了广播级标准,普通人几乎无法分辨合成语音与真实广播语音之间的差异。总体来看,新一代语音大模型的语音表现更为清晰流畅、悦耳动听、易于理解和接受,可以真正应用于影视或游戏角色配音等场景,为用户提供专业级的体验。
TicVoice 7.0的发布不仅彰显了出门问问在人工智能语音生成领域的重要进展,同时也通过开源生态系统与产学研的深度融合,为行业的进一步发展注入了新的动力。这一举措无疑将促进更多创新成果的涌现,推动整个行业迈向更高水平的技术应用和服务优化。同时,这也表明企业在追求技术创新的同时,也越来越重视开放合作,共同构建健康发展的产业生态。
未来,出门问问将持续深化与顶尖学术机构的合作,不断提升用户的产品体验,探索语音生成技术与多模态 AI 的融合边界,从“听得懂”到“听得真”,从“能表达”到“有情感”,让 AI 真正成为人类情感与智慧的延伸。
免责声明:本站所有文章来源于网络或投稿,如果任何问题,请联系648751016@qq.com
页面执行时间0.00921秒