未来已来:GO-1,开启智能革命
3月10日,智元机器人近日推出了其首款通用具身基座大模型:智元启元大模型(GenieOperator-1)。
智源创新性地提出了Vision-Language-Latent-Action (ViLLA) 架构,该架构由VLM(多模态大模型)和MoE(混合专家)构成。其中,VLM通过分析海量互联网图文数据,获得了强大的通用场景理解和语言处理能力。MoE中的LatentPlanner(隐式规划器)则通过分析大量的跨领域及人类操作数据,掌握了通用动作理解能力。同时,MoE中的ActionExpert(动作专家)借助百万级别的真实设备数据,具备了精确的动作执行能力。这三部分相互配合,使系统能够从人类视频中学习,实现小样本快速泛化,从而降低了具身智能的技术门槛。目前,该架构已成功应用于智源多款机器人产品,并持续进行优化升级,推动了具身智能技术的发展。
GO-1:具身智能的全面创新
GO-1大模型通过整合人类和各种机器人数据,使机器人具备了革命性的学习能力,能够广泛应用于不同环境和物体中,迅速掌握新任务和技能。此外,该模型还能适配于各类机器人平台,实现高效部署,并在实际应用中不断快速进化。
这一系列的特点可以归纳为4个方面:
人类视频学习:GO-1大模型能够融合网络视频与实际人类演示进行学习,从而加深了对人类行为的认知,以提供更优质的人类服务。
●小样本快速泛化:GO-1大模型具有强大的泛化能力,能够在极少数据甚至零样本下泛化到新场景、新任务,降低了具身模型的使用门槛,使得后训练成本非常低。
●一脑多形:GO-1大型模型是一种通用机器人策略模型,能够实现在多种机器人形态间的迁移,迅速适应各种不同的本体结构,从而实现群体智能的提升。
●持续进化:GO-1大模型搭配智元一整套数据回流系统,可以从实际执行遇到的问题数据中持续进化学习,越用越聪明。
GO-1:VLA进化到ViLLA
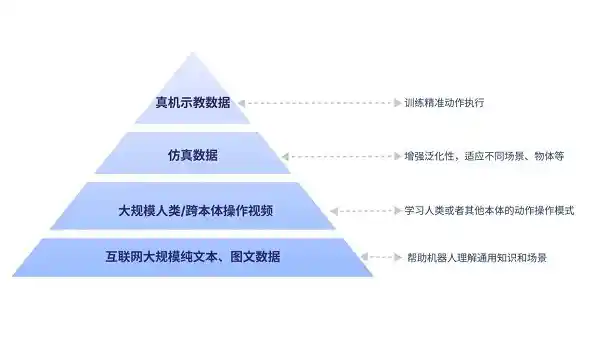
GO-1大模型,基于具身领域的数字金字塔所构建,吸纳了人类世界多种维度和类型的数据,让机器人在一开始就拥有了通用的场景感知和语言能力,通用的动作理解能力,以及精细的动作执行力。
数字金字塔的底层是互联网的大规模纯文本与图文数据,可以帮助机器人理解通用知识和场景。在这之上是大规模人类操作/跨本体视频,可以帮助机器人学习人类或者其他本体的动作操作模式。更上一层则是仿真数据,用于增强泛化性,让机器人适应不同场景、物体等。金字塔的顶层,则是高质量的真机示教数据,用于训练精准动作执行。
现有的VLA(视觉-语言-动作)架构尚未充分利用数字金字塔中的大规模人类/跨领域操作视频数据,这缺失了一个关键的数据来源,从而导致了更高的迭代成本和更缓慢的进化速度。
那么,怎样的架构才能充分利用好这些数据?
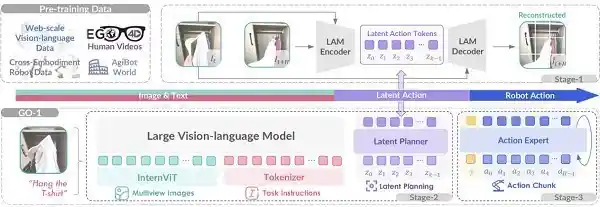
智元提出了全新的Vision-Language-Latent-Action (ViLLA) 架构。与VLA架构相比,ViLLA通过预测Latent Action Tokens(隐式动作标记),弥合了图像-文本输入与机器人执行动作之间的鸿沟,能有效利用高质量的AgiBot World数据集以及互联网大规模异构视频数据,增强策略的泛化能力。基于该架构,智元打造了通用具身基座大模型――GO-1。它由VLM(语言视觉模型)和MoE(专家混合模型)组成,输入为多相机的视觉信号、力觉信号、语言指令等多模态信息,直接输出机器人的动作执行序列。
这样,GO-1大型模型能够协助机器人完成整体的“基础教育”和“职业教育”,使机器人具备天然的适应能力,可以灵活应对各种环境和物体,迅速掌握新的操作技能。
在日常生活中,我们经常需要让机器人帮助我们完成一些特定任务,例如“挂衣服”。这一过程中,机器人首先要理解用户的指令,即通过视觉系统识别出“挂衣服”这项任务。接着,机器人会回想起在训练期间所学习到的相关知识,思考出一系列合适的操作步骤,如找到挂钩、抓住衣物、准确放置等。最终,机器人将按照预设步骤一步步执行,从而成功完成任务。 这样的技术不仅极大地方便了我们的日常生活,还展示了人工智能与机器学习技术的巨大潜力。随着技术的发展,我们可以期待未来会有更多复杂且实用的功能被开发出来,让机器人的帮助更加无处不在,为人们的生活带来更多便利。
在更深层的技术面,因为GO-1大模型在构建和训练阶段,学习了互联网的大规模纯文本和图文数据,所以能理解“挂衣服”在此情此景下的含义和要求;学习过人类操作视频和其他机器人的各种操作视频,所以能知道挂衣服这件事通常包括哪些环节;学习过仿真的不同衣服、不同衣柜、不同房间,模拟过挂衣服的操作,所以能理解环节中对应的物体和环境并打通整个任务过程;最后,因为学习过真机的示教数据,所以机器人能精准完成整个任务的操作。
具体来说,VLM作为一款通用具身基座大模型,承袭了开源多模态大模型InternVL2.5-2B的权重参数,通过利用互联网上的大规模纯文本和图文数据,使GO-1大模型拥有了强大的场景感知和理解能力。
隐动作专家模型作为第一个专家模型,是GO-1大模型中隐式的规划器,它利用到了大规模人类操作和跨本体操作视频,让模型具备动作的理解能力。
GO-1大模型的最终环节是一个专门用于动作预测的动作专家模型,该模型通过利用高质量的仿真数据和实际设备数据,显著提升了动作执行的精确度和可靠性。 这一设计展示了人工智能技术在模拟与现实世界交互中的强大潜力。通过结合仿真环境与真实世界的反馈,GO-1不仅能够学习到更加复杂和精准的动作序列,还能适应各种动态变化的实际操作环境。这种技术的进步对于推动机器人技术的发展具有重要意义,未来有望在工业自动化、医疗手术辅助以及日常生活服务等多个领域发挥关键作用。
智元通用具身基础大模型GO-1的发布,体现了具身智能在通用化、开放化和智能化方面迅速发展:
从专注于单一任务到胜任多种任务:机器人能够适应不同环境并执行各种任务,无需为每项新任务进行重新训练。
从实验室到现实世界:机器人技术不再受制于封闭环境,而是能够应对复杂多变的真实世界场景。
随着技术的进步,机器人已不再受限于预设程序,现在它们能够理解自然语言指令,并通过语义进行组合推理。这一变化不仅极大地提升了机器人的实用性,还意味着人机交互方式正朝着更加自然和高效的方向发展。未来,我们可以期待机器人在家庭、医疗、教育等多个领域发挥更大的作用,带来更加便捷的生活体验。
GO-1大模型将推动具身智能的广泛应用,使机器人从专注于特定任务的设备进化为拥有通用智能的自主系统,在商业、工业和家庭等多个领域展现出更强大的功能,引领我们走向更为通用和全能的智能时代。
免责声明:本站所有文章来源于网络或投稿,如果任何问题,请联系648751016@qq.com
页面执行时间0.008395秒