豆包大模型引爆AI圈:4%幻觉率重塑可信人工智能标杆
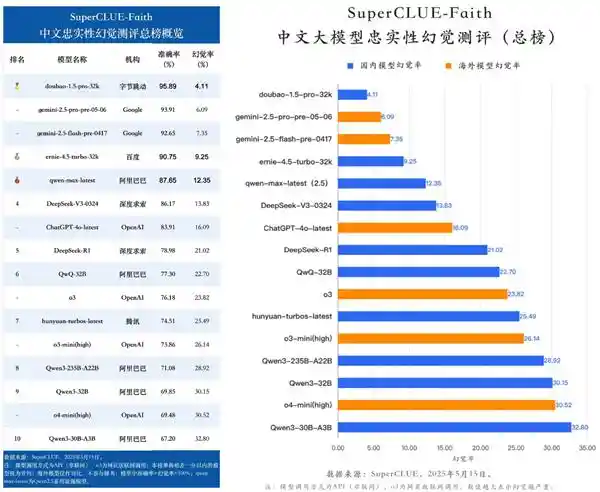
近日,豆包大模型1.5Pro(Doubao-1.5-pro-32k)在SuperCLUE的最新测评中脱颖而出,以4%的超低幻觉率和96%的高准确率荣登总榜榜首,这一成绩不仅彰显了其卓越的技术实力,也标志着国产大模型在忠实性方面取得了突破性的进展。与DeepSeek-R1、DeepSeek-V3、Gemini-2.5-pro以及GPT-4o-latest等国际知名模型相比,豆包大模型的表现尤为亮眼,这无疑为中文大模型领域注入了一剂强心针。 从测评结果来看,豆包大模型在处理复杂任务时展现出极高的精准度,尤其是在需要高度逻辑性和专业性的场景下,其表现更是令人印象深刻。这表明,国产大模型不仅能够满足日常使用需求,还能在特定领域内提供可靠的支持。同时,这也说明国内企业在技术研发上的持续投入正在收获回报,未来有望在全球范围内占据更重要的位置。 此外,豆包大模型的成功还反映了中国科技企业对技术创新的重视。面对激烈的市场竞争,只有不断优化算法、提升性能才能保持领先地位。因此,我们有理由相信,在不久的将来,会有更多像豆包这样的优秀产品涌现出来,为中国乃至世界的科技进步贡献力量。总之,这次测评结果不仅是一次技术上的胜利,更是一个激励人心的消息,它让我们看到了中文大模型发展的无限可能。
豆包大模型1.5Pro在全球多项关键任务评测中表现出色,不仅在文本摘要、多文本问答以及对话补全等领域稳居榜首,其在阅读理解任务中的国内最高准确率更是令人瞩目。这充分展示了该模型在处理复杂语言理解和生成场景时的强大实力。 在我看来,豆包大模型1.5Pro的成绩不仅体现了技术上的突破,也反映了人工智能在自然语言处理领域的持续进步。随着这类技术的发展,我们有理由相信,未来的智能系统将在更多应用场景中发挥更大的作用,为用户带来更加智能化和便捷的服务体验。同时,这也激励着科研人员继续探索更高效、更精准的人工智能解决方案,推动整个行业向前发展。
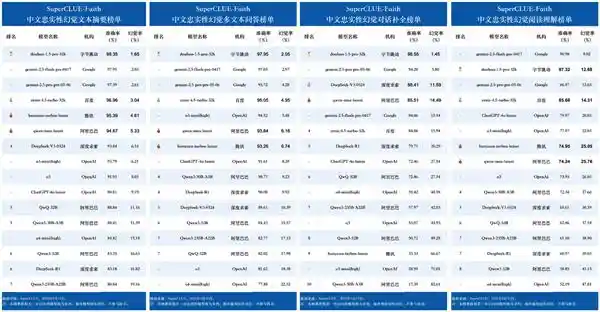
SuperCLUE是由独立第三方打造的中文大语言模型评测基准,其权威性和实用性在行业内备受关注。SuperCLUE-Faith专注于评估中文模型在内容生成过程中对忠实性的把控以及对幻觉现象的管理能力,通过文本摘要、阅读理解、多文本问答及对话补全等多个维度进行测评。此次评估涵盖了国内外共16款代表性模型,其结果具有较高的可信度和实用参考价值。
目前,豆包大模型家族已经全面覆盖了多种模态和应用场景,包括大语言模型、深度思考模型、视觉理解模型、语音大模型,以及图像、视频等视觉大模型。企业和开发者可以通过字节跳动旗下的云服务平台火山引擎来使用豆包大模型提供的API服务。其中,豆包大模型1.5Pro采用了MoE架构,并结合了训练与推理一体化的设计理念,在确保高效性能的同时大幅降低了推理成本。通过激活部分参数,该模型能够针对大规模场景进行精准的理解与生成,其综合表现已经超越多款超大稠密预训练模型。
截至2025年3月底,豆包大模型的日均tokens调用量已突破12.7万亿,这一数字是2024年12月的3倍,也相当于其发布初期的106倍。根据IDC的统计数据,2024年中国公有云大模型的调用量显著增长,其中火山引擎凭借46.4%的市场份额稳居国内市场首位。
据悉,火山引擎计划于6月11日在京召开FORCE原动力大会,届时将展示豆包大模型的最新优化成果与功能提升。这次大会无疑将成为科技领域的一大焦点,不仅体现了火山引擎在人工智能领域的持续投入,也彰显了其推动技术创新的决心。 豆包大模型自推出以来,凭借其强大的性能和广泛的应用场景赢得了市场的认可。此次升级将进一步强化其在自然语言处理、多模态交互等方面的能力,这不仅有助于提升用户体验,也为行业带来了更多可能性。随着人工智能技术的不断进步,我们有理由相信,豆包大模型将在未来的应用场景中发挥更大的作用,为企业和社会创造更多价值。希望未来能有更多类似的创新成果涌现,助力我国人工智能产业迈向新的高度。
免责声明:本站所有文章来源于网络或投稿,如果任何问题,请联系648751016@qq.com
页面执行时间0.013261秒