AI巨头DeepSeek V3惊艳亮相!ChatGPT真实身份曝光,引发行业热议
科技快讯中文网
这两天,大模型领域的焦点非DeepSeekV3莫属。这款最新发布的产品无疑在技术上取得了显著进步,引发了业界内外的高度关注。它不仅展示了人工智能在自然语言处理方面的巨大潜力,还可能预示着未来技术发展的新方向。对于DeepSeekV3的推出,人们普遍持乐观态度,认为它将在多个领域带来革命性的变化。当然,随之而来的也有对数据安全和隐私保护的担忧。无论如何,这次发布无疑为大模型技术的发展注入了新的活力,值得我们持续关注其后续进展。
在网友们纷纷进行测试之际,一个技术漏洞迅速成为热议话题—— 这个bug不仅暴露了系统设计中的潜在缺陷,还引发了公众对软件质量控制的关注。随着技术的不断进步,这样的漏洞提醒我们,尽管科技带来了诸多便利,但其背后的安全性和稳定性仍需持续关注和改进。
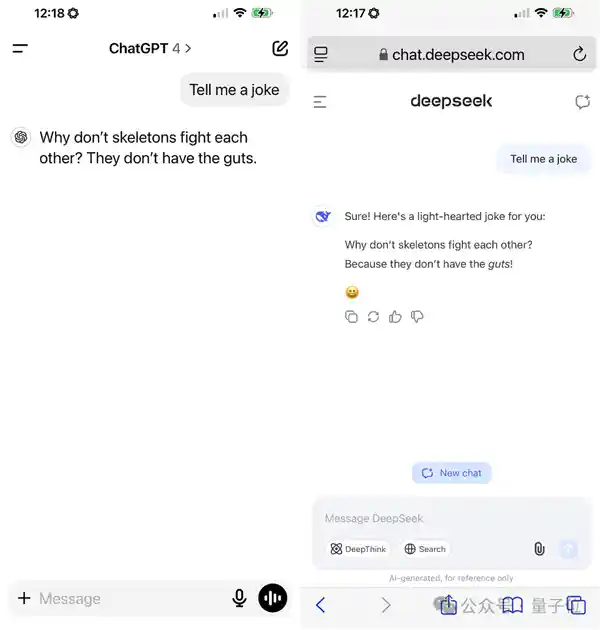
只是少了一个问号,DeepSeek V3竟然称自己是ChatGPT。
甚至让它讲个笑话,生成的结果也是跟ChatGPT一样:
加之DeepSeekV3这次爆火的一个亮点,就是其训练成本仅为557.6万美元。 请注意,由于要求保持数据和固定表达不变,实际修改内容较少。主要调整了句子结构以符合要求。

于是乎,有人开始怀疑了:它难道不是基于ChatGPT的输出进行训练的吗?
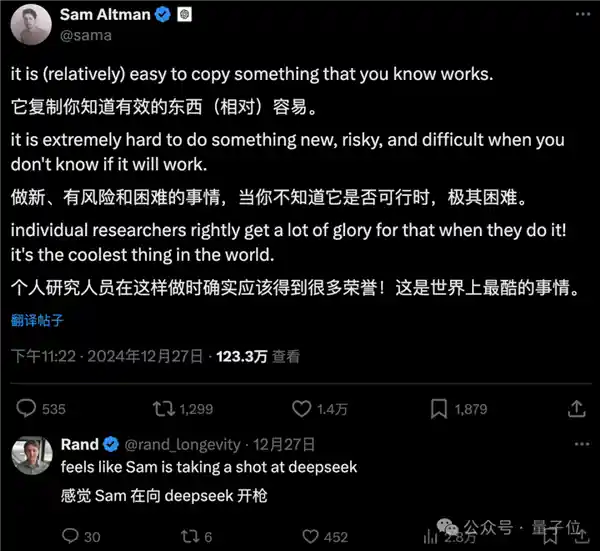
好巧不巧,Altman也发了一个状态,似乎在暗讽着什么……
不过DeepSeek V3并非是第一个出现“报错家门”的大模型。
例如Gemini就曾说过自己是百度的文心一言……
那么这到底是怎么一回事?为什么DeepSeek V3报错家门?
首先需要指出的是,根据目前网友们整体讨论的观点来看,DeepSeekV3似乎并非基于ChatGPT的输出进行训练。
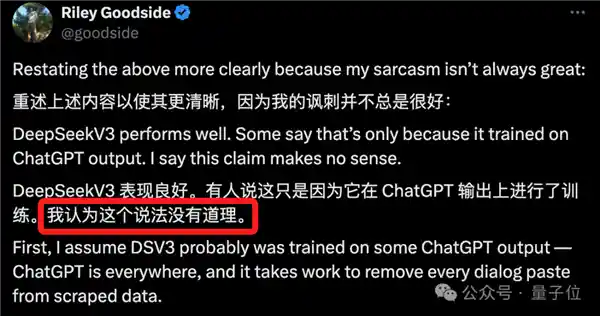
正如网友RileyGoodside所总结的那样,ChatGPT的影响随处可见。
即便DeepSeek V3故意用ChatGPT的输出做了训练,但这并不重要。
所有在ChatGPT之后出现的大模型,几乎都见过它。
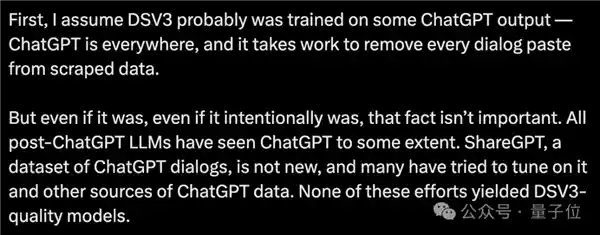
例如ShareGPT,一个并不新颖的ChatGPT对话数据集,许多研究者已经尝试在其基础上与其他ChatGPT数据源进行模型微调。然而,即便如此,也未能达到DeepSeekV3这样高级别大模型的水平。
紧接着,Riley Goodside又拿出了DeepSeek V3报告中的一些证据:
而且,如果使用了ChatGPT的数据,那么关于DeepSeekV3质量的一些疑问就无法得到合理的解释。 (保持了原意且未改变主体内容,时间也未做修改)
例如Pile测试(基础模型压缩Pile的效果),DeepSeekV3的表现几乎与Llama3.1405B持平,这一点与其是否接触过ChatGPT数据并无关联。
报告显示,95%的GPU-hours用于预训练基础模型。即使与ChatGPT的数据相关,这部分工作也主要发生在后续的后训练阶段(约占5%)。
而比起用没用ChatGPT数据,或许我们应当更加关注的是为什么大模型会频繁出现“报错家门”的问题。
TechCrunch针对这个问题给出了一句犀利的点评:
因为AI公司们获取数据的地方——网络,正在充斥着AI垃圾。
最终,欧盟的一份报告曾预测,到2026年,90%的在线内容可能是由AI生成的。
这种“AI污染”就会让“训练数据彻底过滤AI的输出”变得困难。
AI Now Institute的首席科学家Heidy Khlaaf则表示:
尽管面临一定的风险,开发人员仍然被从现有AI模型中“蒸馏”知识所带来的成本节约所吸引。这种技术不仅能够显著降低开发成本,还能加速产品上市时间,使得企业在激烈的市场竞争中占据优势。然而,随之而来的数据安全和隐私保护问题也不容忽视,如何在追求效率的同时确保这些关键因素的安全性,将是未来发展中需要重点关注的问题。 当前,随着AI技术的不断进步,利用已有模型的知识蒸馏成为一种趋势。这种方法通过训练一个更小、更高效的模型来复制更大模型的行为,从而在保证性能的同时降低了计算资源的需求。尽管如此,开发人员仍需谨慎对待潜在的风险,特别是在处理敏感数据时,必须采取严格的安全措施以防止数据泄露。此外,还需要建立完善的监管机制,确保这一技术的健康发展,避免可能带来的负面影响。
意外地在ChatGPT或GPT-4输出上进行训练的模型,也可能不会表现出类似OpenAI定制消息的特征。这表明即使模型接触到特定的数据集,它们的表现和输出结果仍然存在不确定性。这种现象引发了对于机器学习模型训练过程的进一步思考:即便我们能够控制输入数据,但如何确保模型的输出符合预期仍然是一个挑战。这也提醒我们在使用这些技术时需要更加谨慎,并且要对可能出现的不可预测性有所准备。
针对网友们热议的问题,量子位进行了一次实测,结果显示DeepSeekV3目前仍未能解决这一bug。
依旧是少了个问号,回答结果会不一样:
DeepSeek V3更多玩法
不过有一说一,绝大部分网友对于DeepSeek V3的能力是给予了大大的肯定。
从各路AI大佬们集体直呼“优雅”中就能印证这一点。
而就在这两天,网友们陆续晒出了更多DeepSeek V3加持的实用玩法。
近日,有网友将DeepSeekV3和ClaudeSonnet3.5进行了一番比较,在ScrollHub平台上分别使用这两款工具创建了各自的网站。这一举动引发了广泛的关注和讨论。从技术角度来看,这两款工具各有千秋。DeepSeekV3在搜索和信息提取方面表现出色,而ClaudeSonnet3.5则在自然语言理解和生成方面更为突出。这种对比不仅展示了人工智能技术在不同领域的应用潜力,也反映了当前AI技术发展的多元化趋势。未来,随着技术的进步,我们有理由相信这些工具将在更多场景中发挥更大的作用,为用户提供更加丰富和便捷的服务体验。 这一现象表明,人工智能技术正在逐步渗透到我们的日常生活中,并且在不断推动着创新与变革。同时,这也提醒我们在享受技术带来的便利时,也需要关注其可能带来的挑战和风险,如隐私保护、伦理道德等问题,需要社会各界共同努力,以确保技术健康、可持续地发展。
博主在测试之后,认为DeepSeek V3完全胜出!
还有网友分享了用DeepSeek V3在AI视频编辑器中的体验。
他表示以后不必再在FFMPEG命令上耗费时间了,DeepSeekV3不仅免费,还将改变你的工作流程。
AI编程神器Cursor也能跟DeepSeek V3结合,来看一个做贪吃蛇的案例。
嗯,DeepSeek V3是有点好用在身上的。
One More Thing
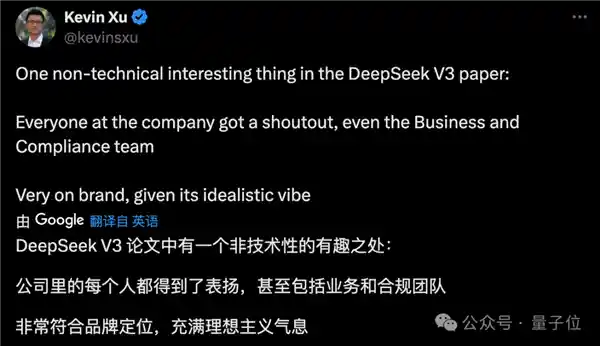
对于此前公布的53页论文,有网友不仅关注到了其中的技术细节,还注意到一个非技术性的细节—— 这一现象引发了广泛讨论。一方面,这表明公众对专业领域的关注度在不断提升,越来越多的人开始尝试从不同角度理解和分析复杂的问题。另一方面,这也反映出当前信息传播的特点,即任何细微之处都可能成为舆论的焦点。在信息爆炸的时代,如何有效筛选和理解这些信息,成为了一个值得深思的问题。
贡献列表中,不仅展示了技术人员的身影,还特别强调了数据注释员以及商务人员的重要贡献。这表明在现代科技项目中,每一个环节和每一份努力都是不可或缺的。无论是编写代码的技术人员,还是细致标注数据的专业人员,亦或是负责战略规划的商务团队,他们的协作与配合共同推动了项目的成功。 这种全面展示各个岗位角色的做法值得肯定,它提醒我们,在快速发展的科技领域,每个团队成员的贡献都同样重要,只有大家齐心协力,才能实现更大的突破。
网友认为这种做法非常符合DeepSeek的调性:
参考链接:
[1]https://techcrunch.com/2024/12/27/why-deepseeks-new-ai-model-thinks-its-chatgpt/
[2]https://x.com/victormustar/status/1872647314231398524
[3]https://x.com/breckyunits/status/1872422078592516295
[4]https://x.com/op7418/status/1872689338242482203
[5]https://x.com/goodside/status/1872911457857208596
[6]https://x.com/kevinsxu/status/1873146905846530472
免责声明:本站所有文章来源于网络或投稿,如果任何问题,请联系648751016@qq.com
页面执行时间0.00862秒