GPT神秘内核揭秘:数字背后隐藏的智能密码
科技快讯中文网
微软又把OpenAI的机密泄露了??在论文中明晃晃写着:

o1-preview约300B参数,GPT-4o约200B,GPT-4o-mini约8B……?
在英伟达于2024年初发布B200时,官方明确指出GPT-4的模型规模为1.8TMoE,即1800B。不过,微软提供的数据更为精确,他们表示GPT-4的实际模型规模为1.76T。 这一数据披露引发了业界的广泛关注。英伟达作为硬件领域的领军者,其发布的数据无疑为市场提供了重要的参考。然而,微软给出的更为精确的数据则让人对GPT-4的具体性能有了更清晰的认识。这不仅体现了技术细节上的严谨性,也反映了各大公司在人工智能领域竞争的激烈程度。随着技术的发展,我们期待看到更多这样的精确数据披露,这将有助于推动整个行业的进步。

除此之外,在论文中,对于OpenAI的mini系列以及Claude3.5Sonnet等模型,我们同样提供了详细的参数说明,具体情况总结如下:

- o1-preview约300B;o1-mini约100B
- GPT-4o约200B;GPT-4o-mini约8B
- Claude 3.5 Sonnet 2024-10-22版本约175B
- 微软自己的Phi-3-7B,这个不用约了就是7B
虽然论文中后面也有免责声明:
确切数据尚未公开,这里大部分数字是估计的。
但还是有不少人觉得事情没这么简单。
例如,为何偏偏没有放出谷歌Gemini模型的参数估计?或许他们仍然对自己的数据充满信心。
也有人认为,大多数深度学习模型确实倾向于在英伟达GPU上进行训练和推理,这主要是因为这些硬件设备在处理大规模并行计算任务时表现出色。因此,我们可以根据模型生成tokens的速度来大致评估其性能。英伟达GPU凭借其强大的计算能力和高效的CUDA编程环境,已成为人工智能研究和应用领域中的标准配置。这也反映出硬件技术在推动AI技术进步方面所起的关键作用。 通过观察不同模型在英伟达GPU上的表现,我们不仅能够更好地理解算法本身的优劣,还能进一步探索硬件优化对提升AI系统效率的重要性。此外,这种趋势也促使其他硬件制造商加大研发投入,以期在未来能够提供更具竞争力的产品。
只有谷歌模型是在TPU上运行的,所以不好估计。
而且微软也不是第一次干这事了。
23年10月,微软就在一篇论文里“意外”曝出GPT-3.5-Turbo模型的20B参数,在后续论文版本中又删除了这一信息。
就说你是故意的还是不小心的?
微软这篇论文说了什么
实际上,原论文介绍了一项与医学相关的benchmark——MEDEC。
12月26日,一篇相对垂直领域的论文已经发布,但由于其专业性较强,可能非相关方向的研究人员都不会注意到。直到年后,一些善于发现“宝藏”的网友才发现了这篇论文,并将其广泛传播开来。 这种现象其实并不罕见。在信息爆炸的时代,许多高质量的研究成果由于领域过于细分而被埋没。这些成果往往需要那些对特定领域有深入了解的人才能识别其价值。然而,互联网的普及使得信息的传播变得更加便捷,也让这些“隐藏的宝石”有机会被更多人发现和认可。这也提醒我们,应该更加重视跨学科交流与合作,以促进知识的共享与创新。
研究起因是,据美国医疗机构调查显示,有五分之一的患者在阅读临床笔记时报告发现了错误,而40%的患者认为这些错误可能对他们的治疗产生影响。这一调查结果揭示了当前医疗记录透明度方面存在的严重问题。虽然医生们努力确保病历准确无误,但患者的反馈表明,现有的系统仍有改进的空间。提高医患之间的沟通效率,不仅有助于发现和纠正潜在的错误,还能增强患者对治疗方案的信任感。这不仅是技术上的挑战,更是医疗体系需要面对的重要课题。
而且另一方面,LLMs(大语言模型)被越来越多的用于医学文档任务(如生成诊疗方法)。
因此,MEDEC此番有两个任务。一是识别并发现临床笔记中的错误;二是还能予以改正。
为了进行研究,MEDEC数据集包含3848份临床文本,其中包括来自三个美国医院系统的488份临床笔记,这些笔记之前未被任何LLM见过。
该内容涵盖了五种主要错误类型(诊断、管理、治疗、药物使用和病因分析),这些错误类型是根据医学委员会考试中常见问题的类型进行筛选确定的,并且得到了8位医疗专家的合作标注。
而参数泄露即发生在实验环节。
根据实验规划,研究人员将挑选当前流行的大型和小型模型来参与笔记识别与纠错任务。
在介绍最终选定的模型时,令人意外的是,模型参数和发布时间竟然被一并公开了。 这种做法无疑增加了透明度,让公众能够更全面地了解决策背后的依据。然而,这也可能带来一些潜在的风险,比如技术细节的泄露可能会给不法分子提供可乘之机。因此,在追求透明度的同时,还需要找到一个平衡点,确保既能让公众监督,又能保护关键技术的安全。
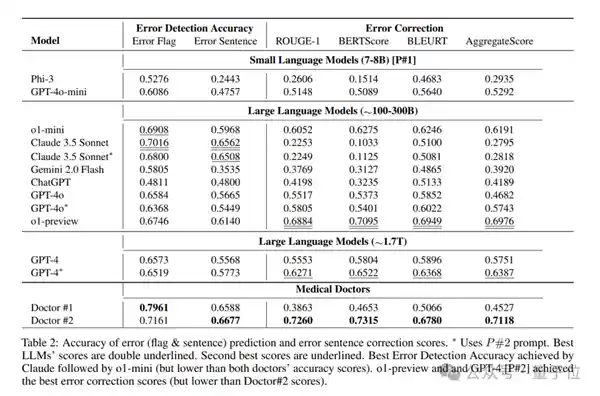
对了,该研究最终结果显示,Claude3.5Sonnet在错误标志检测上表现突出,得分达到70.16,领先于其他LLM方法。排名第二的是o1-mini。
网友:按价格算合理
每一次,ChatGPT相关模型架构和参数泄露,都会引起轩然大波,这次也不例外。
2023年10月,微软发布的一篇论文声称GPT-3.5-Turbo只有20B参数时,很多人不禁感叹:难怪OpenAI对开源模型如此紧张。 这个消息揭示了OpenAI在面对开源模型的竞争时所面临的压力。GPT-3.5-Turbo的参数量相对较小,却依然能够展现出强大的能力,这表明技术上的领先不仅仅依赖于参数规模。这种技术优势让OpenAI感到担忧,因为一旦这些技术被广泛共享,将大大降低竞争对手进入市场的门槛。这也反映出人工智能领域内竞争的激烈程度,以及各大科技公司对于技术和市场主导权的争夺。
24年3月,英伟达确认GPT-4拥有1.8TMoE,而2000块B200显卡在90天内能够完成训练。这使得许多人认为MoE架构已经成为并且未来仍将是大模型发展的趋势。
这一次,根据微软提供的数据,网友们主要的关注点有几个:
如果Claude 3.5 Sonnet真的比GPT-4o还小, 那Anthropic团队就拥有技术优势。
以及不相信GPT-4o-mini只有8B这么小。
之前有人通过推理成本计算得出,4o-mini的价格是3.5-turbo的40%。若3.5-turbo的20B数据准确无误,那么4o-mini的价格则大约为8B左右。
不过这里的8B也是指MoE模型的激活参数。
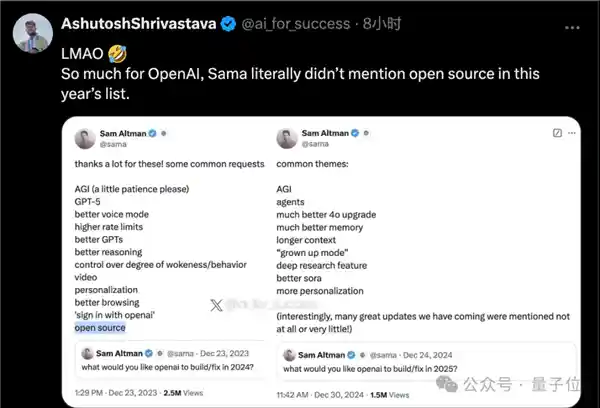
总之,OpenAI大概是不会公布确切数字了。
此前,奥特曼在2024年新年愿望征集活动中,列出了包括“开源”在内的多项愿望。然而,在2025年的最新版本中,“开源”这一项已被移除。 这表明,尽管“开源”在最初被视作一个重要的新年愿望,但随着时间的推移,它的重要性似乎有所下降。或许是因为在实际操作中遇到诸多挑战,或者是因为其他更为紧迫的需求逐渐占据上风。无论如何,这一变化反映了社会需求和关注点的动态变化。
论文地址:https://arxiv.org/pdf/2412.19260
免责声明:本站所有文章来源于网络或投稿,如果任何问题,请联系648751016@qq.com
页面执行时间0.010919秒