数学算力争霸:讯飞星火 X1 升级版 VS DeepSeek
3月3日,科大讯飞对星火深度推理模型X1进行了全面升级,并首次推出了基于星火X1的星火医疗大模型X1。该模型在疾病诊断和健康建议等医学任务上表现卓越。
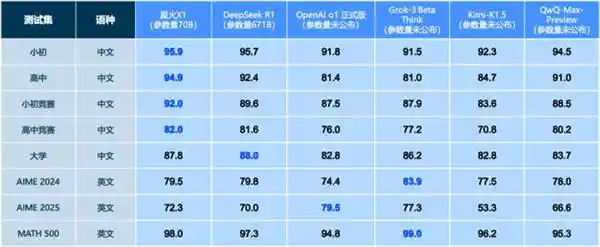
作为国内首个且目前唯一一个完全使用国产算力进行训练的深度推理大模型,星火X1在参数量较小的情况下,其数学能力可与DeepSeekR1和OpenAIo1相媲美;讯飞星火X1的更新迭代,展示了基于国产算力训练的全栈自主可控大模型具有强大的实力和创新潜能。

测试数据来源:中文测试集取自2023/2024年度各阶段考试真题、模拟题及竞赛题,英文测试集则源自AIME2024/2025和MATH500竞赛题。

我们在星火X1升级后的第一时间,将其数学能力和DeepSeek做了简单对比,用的5道测试题含金量颇高,全部来自《2024年全国统一高考数学试卷(新高考Ⅰ)》,两大模型答卷情况如下:

小提示:由于高考试题难度较大,大模型提供的解题过程通常较长,使用截图方式难以一次性截取完整内容,可能需要分两次截取。因此,下面提供了同一问题的两部分解答截图。
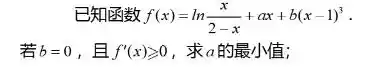
题目1:

甲、乙两人各有四张卡片,每张卡片上标有一个数字,甲的卡片上分别标有数字1,3,5,7,乙的卡片上分别标有数字2,4,6,8,两人进行四轮比赛,在每轮比赛中,两人各自从自己持有的卡片中随机选一张,并比较所选卡片上数字的大小,数字大的人得1分,数字小的人得0分,然后各自弃置此轮所选的卡片(弃置的卡片在此后轮次中不能使用).则四轮比赛后,甲的总得分不小于2的概率是多少?

星火X1解答如下:

DeepSeek R1解答如下:

星火XI开门红,先胜一局,给出了正确答案,且解题过程相当清楚。DeepSeek大意失荆州,给出了错误答案。
题目2:
星火X1解答如下:
DeepSeek R1解答如下:
这局表现整体不错,两款大模型都给出的正确答案,看来DeepSeek终于睡醒了,老虎要发威了。
题目3:
星火X1解答如下:
DeepSeek解答如下:
两大模型再接再厉,并驾齐驱,再度拿下一城。
题目4:
星火X1解答如下:
DeepSeek R1解答如下:
这是一道典型的等差数列问题,两大模型都得出了正确的解答,值得称赞!
题目5:
星火X1解答如下:
DeepSeek解答如下:
星火X1解答正确,DeepSeek刚展现出来的猛劲似乎又过了,在一道看起来并不很难的题上栽了跟头,错失一城。
小结:
至此,笔者兴致勃勃举办的这场友谊赛暂告结束,从整场赛事的表现来看,两款大模型在解答问题前,都会进行类人思考,并将思考过程完整呈现出来,其中包括题意分析,解题过程中要用到的知识点及详细的推理逻辑等,并会在发现问题时及时反思、纠错,应该说这一功能相当有用。因为它会让用户在得到答案的同时,知其然,更知其所以然,从而举一反三,弄懂一大类题的解法。
除此之外,该系统还支持图像识别解题,其识别准确率非常高。不论是手机拍摄的纸质试卷或作业,还是网络截图,都能轻松识别并解答。这一特性解决了使用键盘输入数学公式和图形时遇到的难题,为用户带来了极大的便利。
只是在解题正确率方面,两大模型表现出一定差异,相比之下,星火X1的正确率要更高一些,5题全对,成为本次“摸底考试”的“尖子生”,DeepSeek则失误了两题,以一道题20分,满分100来算,此次比赛刚好及格。
讯飞星火深度推理大模型X1升级版之所以展现出色的表现,可能与其新增的两项创新技术密切相关。这两项新技术不仅增强了模型的推理能力,还显著提升了其在处理复杂任务时的准确性与效率。这些改进无疑为人工智能领域带来了新的突破,也预示着未来该模型在实际应用中的广阔前景。随着技术的不断进步,我们有理由期待这类高级模型将在更多场景中发挥重要作用,推动科技更好地服务于社会。
这一先进技术通过自动化的高效领域数据挖掘和多种数据合成算法,创建了庞大的数学领域预训练数据库,从而大幅增强了基础模型在数学专业方面的实力。
二是通过运用评语模型与强化学习算法,成功激活了大模型的长思维链。此外,评语模型还能促使大模型在推理过程中进行自我反思和验证,从而进一步提高了模型在推理阶段的准确性。
免责声明:本站所有文章来源于网络或投稿,如果任何问题,请联系648751016@qq.com
页面执行时间0.008922秒