探索未知领域!突破性存储方案震撼登场,DeepSeek-R1带您开启数据新境界
自从DeepSeek-R1问世以来,它便在科技界引发了热烈的讨论。此款模型不仅融合了先进的“思维链”技术,使其在处理复杂任务时表现出了卓越的推理能力,而且通过一系列算法优化措施,显著降低了本地部署的经济成本。尽管如此,拥有671B参数规模的DeepSeek-R1对于硬件配置仍然提出了较高要求。 从当前的发展趋势来看,DeepSeek-R1无疑为人工智能领域树立了一个新的标杆。它所采用的“思维链”技术不仅展示了强大的逻辑分析能力,还预示着未来AI系统可能达到的高度智能化水平。然而,高昂的硬件需求也提醒我们,在追求技术创新的同时,还需考虑实际应用中的可操作性和普及性。如何平衡技术进步与成本控制,将是未来人工智能发展过程中需要持续关注的重要议题。
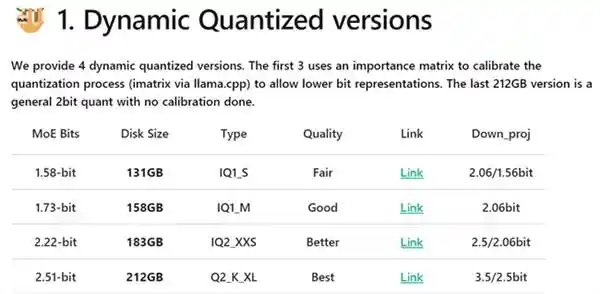
那么,通过应用特定的量化技术,我们可以显著减小已有强大AI模型的体积,从而大大降低本地部署的成本。这种方法不仅能够帮助企业和研究机构在有限的预算内实现高效的人工智能应用,还能够推动AI技术的普及与应用范围的扩大。 这种创新的技术方案为AI模型的广泛应用提供了一种更为经济的选择。它不仅有助于降低成本,还能提高效率,使得更多的中小企业和个人开发者有能力使用先进的AI工具,这无疑会加速人工智能领域的整体发展。

什么是动态量化
动态量化技术针对DeepSeekR1模型中的关键层采用4到6比特的高精度量化,而对于非关键的混合专家层(MoE)则应用更激进的1到2比特量化策略。通过这种方式,该模型可以被压缩至最低131GB(1.58比特量化),在保持参数规模的同时,显著降低了本地部署的要求。
模型选择与配置方案
为了实现更低的部署成本,我们这次选择了131GB大小的1.58位量化模型,同时采用了云翼(UniWhen)“珑”系列DDR5 192GB(48GB*4)套条来替代传统的显存方案。 这一策略不仅有效降低了硬件成本,还显著提高了系统的整体效能。通过使用更为经济高效的1.58位量化模型,我们能够在不牺牲性能的前提下大幅减少内存占用,这为我们的项目在预算有限的情况下提供了更多可能性。同时,云翼(UniWhen)“珑”系列DDR5内存的引入也显示了公司在追求技术创新和高效能方面的不懈努力。这种创新的存储解决方案不仅能提供更大的带宽和更快的数据访问速度,还能够满足大规模数据处理的需求,这对于推动项目进展至关重要。
云彣(UniWhen®)作为紫光国芯旗下的品牌,以其独特的国韵设计风格脱颖而出。其「珑」系列DDR5 192GB套条专为高性能和大容量存储需求而设计,单条容量更是高达48GB。这不仅能够充分支持满血版DeepSeekR1的本地部署,还通过使用高品质原厂颗粒和十层PCB堆叠设计,确保了在AI运算中的出色表现。经过云彣(UniWhen)严格的二级验证测试,该系列产品显示出极高的兼容性,能够广泛适配市面上的主流主板,并且支持Intel XMP3.0和AMD EXPO一键超频技术,使得用户能够在无需复杂设置的情况下,轻松体验到高效的系统性能和数据处理能力。 这一系列产品的推出,无疑为追求高性能和大容量存储解决方案的专业用户提供了更多选择。它不仅体现了云彣在技术创新方面的持续努力,也展示了其对市场需求的深刻理解。随着AI技术的快速发展,这类能够提供强大支持的产品显得尤为重要,它们将有助于推动相关行业的发展与进步。
外观设计层面,云彣(UniWhen)「珑」系列DDR5 192GB套条从传统文化中汲取灵感,以“龙”元素为主题,配合古代城楼的“飞檐翘角”,令华贵、庄严气质扑面而来。其还提供云锦白与朱砂红两款色泽任君择选,以便彰显个性品味。若追求RGB氛围,则可选择相同设计的云彣(UniWhen)「煌」系列,其顶部覆有1600万色雾化导光条,且支持灯光同步功能。
实战部署指南
下载 LM Studio:访问 GitHub页面 或 官方网站 获取最新版本的安装包和官方文档。
运行安装:以Windows为例,下载安装包后双击运行,等待安装启动和自动结束并打开界面。
下载模型:从Hugging Face网站下载unsloth DeepSeek-R1 GGUF 1.58-bit量化模型。
模型配置与微调:在LM Studio设置中选择CPU llama,使用内存加载AI模型。
DeepSeek R1本地部署体验
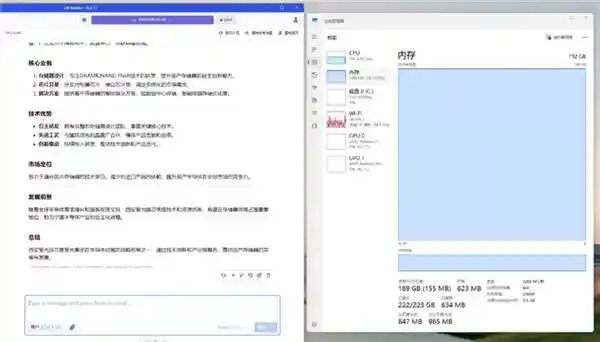
在上下文长度设定为20000的情况下,仅使用CPU进行运算时,DeepSeek R11.5 8-bit量化模型在云彣(UniWhen)「珑」系列DDR5 192GB内存套件的支持下,表现出色。该模型达到了每秒处理2.44万亿次运算的速度,同时内存使用量高达189GB,几乎完全占用了全部内存资源。这样的性能指标表明,在日常的任务中,用户可以享受到较为流畅的问答体验。 从技术角度来看,这无疑是一大进步。尤其是在利用8位量化技术降低计算复杂度的同时,还能保持如此高的运算效率,显示出该模型在处理大规模数据集时的强大能力。然而,值得注意的是,尽管硬件配置已经非常强大,但仅依赖CPU进行运算可能在某些情况下会成为瓶颈。未来的研究或许应该更多地考虑如何更好地整合GPU或其他加速器,以进一步提升处理速度和效率。此外,对于内存占用率接近100%,也提醒我们后续需要关注优化算法或增加内存容量,以确保系统在运行大型任务时的稳定性和可靠性。
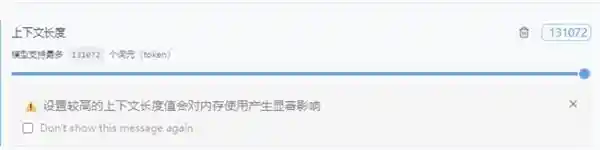
对于有长文本对话需求的用户,可以考虑使用70B蒸馏模型。在最大131072上下文长度的情况下,云彣(UniWhen)「珑」系列DDR5 192GB内存条仍然能够完整加载该模型,并高效完成处理百万字小说所需的数据任务。实际内存使用量为90GB,占用率为47%,冗余非常充足。
低成本部署的理想之选
随着AI算力需求不断攀升,如何以更低的成本实现本地化部署,成为中小型企业及个人用户共同面临的挑战。为此,云彣(UniWhen)推出了「珑」系列DDR5 192GB内存条,不仅能够完美支持全功能的DeepSeekR1模型,提供更加智能化的AI体验,还在高强度运算中展现出卓越的稳定性和高效性。相比传统的显存方案,「珑」系列内存条无疑为预算有限的用户提供了更优的选择。
免责声明:本站所有文章来源于网络或投稿,如果任何问题,请联系648751016@qq.com
页面执行时间0.01153秒